2012년 3월 28일 수요일
Single functions
문자 함수
LOWER: 전부 소문자로
UPPPER: 전부 대문자로
INITCAP: 맨 앞만 대문자로
CONCAT('Hello', 'World')=> HelloWorld
SUBSTR('HelloWorld',1,5)=> Hello
LENGTH('HelloWorld')=> 10 INSTR('HelloWorld', 'W')=> 6
LPAD(salary,10,'*')=> *****24000 =LPAD(' ',10,'*') 식으로도 가능 RPAD(salary, 10, '*')=> 24000*****
REPLACE('JACK and JUE','J','BL')=> BLACK and BLUE
TRIM('H' FROM 'HelloWorld')=> elloWorld =첫글자나 맨 뒤글자만 됨
숫자 함수
ROUND
TRUNC
MOD: 나머지값
날짜 함수
SYSDATE
※date+number = number를 일수로 계산함, 결과는 date
date-number = 위와 마찬가지, 결과는 date
date-date = 둘의 차이를 일수로 계산하여 보여줌, 결과는 일수
date+number/24 = 일수/24이므로 시간임. 시간을 + 계산하여 결과로 date를 보여줌
MONTHS_BETWEEN('date1', 'date2'): 두 날짜사이의 달수를 계산함
ADD_MONTHS('date1', number): date1에서 number만큼의 달수를 더함
NEXT_DAY('date', 'monday'):date의 다음 월요일을 나타냄
LAST_DAY('date'):해당 달의 마지막날을 나타냄
ROUND(SYSDATE,'MONTH'):16일 이후는 반올림하여 다음달로 표시함.
ROUND(SYSDATE,'YEAR'):7월 1일 이후는 반올림하여 다음 해로 표시함.
TRUNC(SYSDATE,'MONTH'):그 달의 1일로 표시함.
TRUNC(SYSDATE,'YEAR'):해당 년도의 1월 1일로 표시함.
변환 함수
TO_CHAR(date,'[fm]format_model')
TO_CHAR(number, 'format_model')
TO_NUMBER(char[, 'format_model'])
TO_DATE(char[, '[fx]format_model'])
NULL 함수
NVL(expr1, expr2): expr1에 있는 NULL 값을 전부 expr2를 리턴, date, number, char, varchar2 다 가능, 주의! expr1과 expr2는 데이터타입이 같아야함. 틀리면 to_char, to_num으로 바꿔서 해야댐.
NVL2(expr1, expr2, expr3): expr1에 있는 값이 널이 아니면 expr2를, 널이면 expr3를 리턴
NULLIF(expr1, expr2): expr1과 expr2가 같으면 null을 리턴하고, 같지 않으면 expr1을 리턴
COALESCE(expr1, expr2, ...exprn): expr1이 null이 아니면 expr1을 리턴, null이면 expr2를 리턴, expr1과 expr2가 null이면 expr3을 리턴)
IF-THEN-ELSE 식 함수
CASE expr WHEN comparison_expr1 THEN return1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
예시)
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END AS "REVISED_SALARY"
FROM employees;
DECODE(col|expression, search1, result1
[, search2, result2,...,]
[, default])
예시)
SELECT last_name, job_id, salary,
DECODE(job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary)
AS REVISED_SALARY
FROM employees;
LOWER: 전부 소문자로
UPPPER: 전부 대문자로
INITCAP: 맨 앞만 대문자로
CONCAT('Hello', 'World')=> HelloWorld
SUBSTR('HelloWorld',1,5)=> Hello
LENGTH('HelloWorld')=> 10 INSTR('HelloWorld', 'W')=> 6
LPAD(salary,10,'*')=> *****24000 =LPAD(' ',10,'*') 식으로도 가능 RPAD(salary, 10, '*')=> 24000*****
REPLACE('JACK and JUE','J','BL')=> BLACK and BLUE
TRIM('H' FROM 'HelloWorld')=> elloWorld =첫글자나 맨 뒤글자만 됨
숫자 함수
ROUND
TRUNC
MOD: 나머지값
날짜 함수
SYSDATE
※date+number = number를 일수로 계산함, 결과는 date
date-number = 위와 마찬가지, 결과는 date
date-date = 둘의 차이를 일수로 계산하여 보여줌, 결과는 일수
date+number/24 = 일수/24이므로 시간임. 시간을 + 계산하여 결과로 date를 보여줌
MONTHS_BETWEEN('date1', 'date2'): 두 날짜사이의 달수를 계산함
ADD_MONTHS('date1', number): date1에서 number만큼의 달수를 더함
NEXT_DAY('date', 'monday'):date의 다음 월요일을 나타냄
LAST_DAY('date'):해당 달의 마지막날을 나타냄
ROUND(SYSDATE,'MONTH'):16일 이후는 반올림하여 다음달로 표시함.
ROUND(SYSDATE,'YEAR'):7월 1일 이후는 반올림하여 다음 해로 표시함.
TRUNC(SYSDATE,'MONTH'):그 달의 1일로 표시함.
TRUNC(SYSDATE,'YEAR'):해당 년도의 1월 1일로 표시함.
변환 함수
TO_CHAR(date,'[fm]format_model')
TO_CHAR(number, 'format_model')
TO_NUMBER(char[, 'format_model'])
TO_DATE(char[, '[fx]format_model'])
NULL 함수
NVL(expr1, expr2): expr1에 있는 NULL 값을 전부 expr2를 리턴, date, number, char, varchar2 다 가능, 주의! expr1과 expr2는 데이터타입이 같아야함. 틀리면 to_char, to_num으로 바꿔서 해야댐.
NVL2(expr1, expr2, expr3): expr1에 있는 값이 널이 아니면 expr2를, 널이면 expr3를 리턴
NULLIF(expr1, expr2): expr1과 expr2가 같으면 null을 리턴하고, 같지 않으면 expr1을 리턴
COALESCE(expr1, expr2, ...exprn): expr1이 null이 아니면 expr1을 리턴, null이면 expr2를 리턴, expr1과 expr2가 null이면 expr3을 리턴)
IF-THEN-ELSE 식 함수
CASE expr WHEN comparison_expr1 THEN return1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
예시)
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END AS "REVISED_SALARY"
FROM employees;
DECODE(col|expression, search1, result1
[, search2, result2,...,]
[, default])
예시)
SELECT last_name, job_id, salary,
DECODE(job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary)
AS REVISED_SALARY
FROM employees;

ALTER 사용법(작성중)
1. 컬럼 추가
형식
ALTER TABLE table
ADD (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
ADD (job_id VARCHAR2(9);
2. 컬럼 변경
형식
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
MODIFY (job_id VARCHAR2(20));
3. 컬럼 제거
형식
ALTER TABLE table
DROP COLUMN column;
예시
ALTER TABLE dep80
DROP COLUMN job_id;
형식
ALTER TABLE table
ADD (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
ADD (job_id VARCHAR2(9);
2. 컬럼 변경
형식
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
MODIFY (job_id VARCHAR2(20));
3. 컬럼 제거
형식
ALTER TABLE table
DROP COLUMN column;
예시
ALTER TABLE dep80
DROP COLUMN job_id;
2012년 3월 27일 화요일
TABLE 생성 및 관리(작성중)
테이블/열 이름 규칙
-문자로 시작
-1~30자까지 가능
-특수문자는 _, $, #만 가능
* CREATE TABLE
1. CREATE 형식: CREATE TABLE table (column datatype)
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr])
다른 유저의 테이블을 보고 싶을때 schema를 사용
schema란=특정 유저가 소유하고 있는 모든 객체들의 집합을 스키마라 하고 이름을 유저이름으로 함
남의 테이블을 참조할때는 반드시 스키마를 명시해야함
예) user hr이 scott의 emp테이블을 보고 싶을때
select * from scott.emp
다른 유저의 것을 볼때는 스키마 생략 불가
DEFAULT 옵션은 값을 입력하지 않을때 자동으로 들어가는 값
다른 컬럼의 이름, nextval, currval은 못쓴다.
예)
CREATE TABLE hire_dates
(id NUMBER(8),
hire_date DATE DEFAULT SYSDATE);
2. CREATE
CREATE TABLE emp
( emp_id number(6) constraint emp_empid_pk primary key,
f_name varchar2(20),
l_name varchar2(25) constraint emp_lname_nn not null,
email varchar2(25) constraint emp_email_nn not null
constraint emp_email_uk unique,
phone_number varchar2(20),
hire_date date constraint emp_hiredate_nn not null,
job_id varchar2(10) constraint emp_jobid_nn not null,
salary number(8,2) constraint emp_salary_ck check (salary>0),
commission_pct number(2,2),
manager_id number(6),
department_id number(4) constraint emp_depid_fk references departments (department_id));
-문자로 시작
-1~30자까지 가능
-특수문자는 _, $, #만 가능
* CREATE TABLE
1. CREATE 형식: CREATE TABLE table (column datatype)
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr])
다른 유저의 테이블을 보고 싶을때 schema를 사용
schema란=특정 유저가 소유하고 있는 모든 객체들의 집합을 스키마라 하고 이름을 유저이름으로 함
남의 테이블을 참조할때는 반드시 스키마를 명시해야함
예) user hr이 scott의 emp테이블을 보고 싶을때
select * from scott.emp
다른 유저의 것을 볼때는 스키마 생략 불가
DEFAULT 옵션은 값을 입력하지 않을때 자동으로 들어가는 값
다른 컬럼의 이름, nextval, currval은 못쓴다.
예)
CREATE TABLE hire_dates
(id NUMBER(8),
hire_date DATE DEFAULT SYSDATE);
2. CREATE
CREATE TABLE emp
( emp_id number(6) constraint emp_empid_pk primary key,
f_name varchar2(20),
l_name varchar2(25) constraint emp_lname_nn not null,
email varchar2(25) constraint emp_email_nn not null
constraint emp_email_uk unique,
phone_number varchar2(20),
hire_date date constraint emp_hiredate_nn not null,
job_id varchar2(10) constraint emp_jobid_nn not null,
salary number(8,2) constraint emp_salary_ck check (salary>0),
commission_pct number(2,2),
manager_id number(6),
department_id number(4) constraint emp_depid_fk references departments (department_id));
2012년 3월 26일 월요일
TCL
Transaction Control Language
DML은 마지막에 TCL이 필요함
트랜잭션 길이가 짧고 갯수가 많은 상황: 은행=OLTP
트랜잭선 길이가 길고 갯수가 적은 상황: dw or batch
※ iSQLPLUS에서 autocommit on을 하면 절대 안된다.
아래 한장으로 대략 거의 모든 설명이 된다.
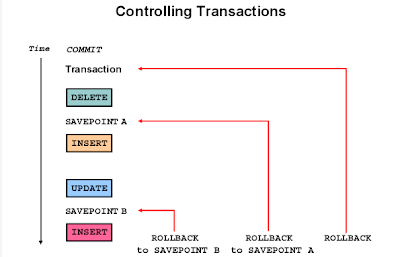
1. 명령어들
COMMIT
SAVE POINT name
ROLLBACK
ROLLBACK TO SAVEPOINT name
2. COMMIT, ROLLBACK이 자동으로 되는 상황
exit를 하면 명시적으로 commit이 발생됨(iSQLPLUS가 정상적으로 종료되어도)
장애 발생하면 자동 rollback 처리됨(iSQLPLUS 창을 닫으면 비정상 종료로 처리함)
DDL = auto commit
DCL = auto commit
3. PENDING STATE: DML을 치고 TCL을 아직 안친 상태
데이터를 이전으로 ROLLBACK 가능
SELECT로 DML 결과를 검토 가능
다른 사용자는 DML 전의 상태만 볼수 있음
DML 작업중인 행은 LOCK 상태이기에 다른 사용자는 변경 불가
4. Read Consistency
-데이터는 항상 commit된 데이터만 보여줘야 한다.
-데이터를 읽는 중(select)에는 다른 사용자가 쓸(insert,update,delete) 수 없다.
-데이터를 쓰는 중에는 다른 사용자가 쓰는 내용을 읽을 수 없다.
5. Read Consistency 구현
-쓰기: select, insert, delete 할 경우 이전 데이터의 복사본을 undo segment에 넣어두고 다른 사용자가 select를 실행시 undo segment 내용을 보여줌.
-커밋되면: undo segment가 지워짐.
-롤백되면: undo segment 내용을 data block으로 다시 이전됨.
DML은 마지막에 TCL이 필요함
트랜잭션 길이가 짧고 갯수가 많은 상황: 은행=OLTP
트랜잭선 길이가 길고 갯수가 적은 상황: dw or batch
※ iSQLPLUS에서 autocommit on을 하면 절대 안된다.
아래 한장으로 대략 거의 모든 설명이 된다.

1. 명령어들
COMMIT
SAVE POINT name
ROLLBACK
ROLLBACK TO SAVEPOINT name
2. COMMIT, ROLLBACK이 자동으로 되는 상황
exit를 하면 명시적으로 commit이 발생됨(iSQLPLUS가 정상적으로 종료되어도)
장애 발생하면 자동 rollback 처리됨(iSQLPLUS 창을 닫으면 비정상 종료로 처리함)
DDL = auto commit
DCL = auto commit
3. PENDING STATE: DML을 치고 TCL을 아직 안친 상태
데이터를 이전으로 ROLLBACK 가능
SELECT로 DML 결과를 검토 가능
다른 사용자는 DML 전의 상태만 볼수 있음
DML 작업중인 행은 LOCK 상태이기에 다른 사용자는 변경 불가
4. Read Consistency
-데이터는 항상 commit된 데이터만 보여줘야 한다.
-데이터를 읽는 중(select)에는 다른 사용자가 쓸(insert,update,delete) 수 없다.
-데이터를 쓰는 중에는 다른 사용자가 쓰는 내용을 읽을 수 없다.
5. Read Consistency 구현
-쓰기: select, insert, delete 할 경우 이전 데이터의 복사본을 undo segment에 넣어두고 다른 사용자가 select를 실행시 undo segment 내용을 보여줌.
-커밋되면: undo segment가 지워짐.
-롤백되면: undo segment 내용을 data block으로 다시 이전됨.
DML 정리(TCL제외)
DML-insert, update, delete
-sql의 CORE
TCL-commit, rollback
* INSERT
1. INSERT 형식: INSERT INTO VALUE
- INSERT INTO table (column1, column2, ...)
VALUES (value1, value2 ...);
- INSERT INTO table
VALUES (value1, value2 ...);
=value 값을 순서에 맞게 다 적어야함
예제)
insert into dep(dep_id, dep_name, man_id, loc_id)
values(75, 'dba',100, 1700);
- Null값을 넣는 방법
1) Implicit method: dep_id, dep_name, man_id, loc_id 가 있으나 생략됐기에 null이 들어감
INSERT INTO dep (dep_id, dep_name)
VALUES (30, 'Purchasing')
2) Explicit method: 직접 null을 명시해서 null값이 들어가게 함
INSERT INTO dep
VALUES (30, 'Purchasing', NULL, NULL);
2. INSERT를 이용한 테이블 복사
- 특정 부분만
INSERT INTO sales_reps(id, name, sal, commission_pct)
SELECT emp_id, l_name, sal, commission_pct
FROM emp
WHERE job_id LIKE '%REP%';
- 전부 복사: 백업이나 마이그레이션을 하는 방법의 주가 될 수 있음
다른 테이블의 내용을 복사해서 내 테이블에 넣는 방법 or 그 반대=데이터를 복사하는 방법
서브쿼리를 사용. 'CTAS'라고도 함
CREATE TABLE copy_emp
AS SELECT *
FROM employees = 여기까지 하면 구조와 data 전부를 복사함
WHERE 1=2 = 이 조건을 주면 맞는 데이터가 전혀 없기 때문에 구조만 복사됨
- Insert에 테이블 대신 서브쿼리 이용 예제
INSERT INTO
(SELECT employee_id, last_name,
email, hire_date, job_id, salary,
department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
* UPDATE
1. UPDATE 형식: UPDATE SET WHERE
- UPDATE table
SET column = value
WHERE condition;
WHERE 절을 안쓰면 전부를 바꿀수 있음 조심
- 여러 값을 서브쿼리를 이용해 바꾸고자 할때.
update emp
set job_id=(select job_id from emp where emp_id=205),
sal=(select sal from emp where emp_id=205)
where emp_id=114;
* DELETE
1. DELETE 형식: DELETE WHERE
- DELETE table
WHERE condition;
예제1) 1개만 지워진다
DELETE FROM departments
WHERE department_name = 'Finance';
예제2) 모두 지워진다- 조심
DELETE FROM copy_emp;
- 다른 테이블을 이용한 열 삭제 예제
DELETE FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE department_name
LIKE '%Public%');
그러나 아마 연관된 레코드가 있다며 무결성 제약 오류가 날 가능성이 크다.(외래키)
-sql의 CORE
TCL-commit, rollback
* INSERT
1. INSERT 형식: INSERT INTO VALUE
- INSERT INTO table (column1, column2, ...)
VALUES (value1, value2 ...);
- INSERT INTO table
VALUES (value1, value2 ...);
=value 값을 순서에 맞게 다 적어야함
예제)
insert into dep(dep_id, dep_name, man_id, loc_id)
values(75, 'dba',100, 1700);
- Null값을 넣는 방법
1) Implicit method: dep_id, dep_name, man_id, loc_id 가 있으나 생략됐기에 null이 들어감
INSERT INTO dep (dep_id, dep_name)
VALUES (30, 'Purchasing')
2) Explicit method: 직접 null을 명시해서 null값이 들어가게 함
INSERT INTO dep
VALUES (30, 'Purchasing', NULL, NULL);
2. INSERT를 이용한 테이블 복사
- 특정 부분만
INSERT INTO sales_reps(id, name, sal, commission_pct)
SELECT emp_id, l_name, sal, commission_pct
FROM emp
WHERE job_id LIKE '%REP%';
- 전부 복사: 백업이나 마이그레이션을 하는 방법의 주가 될 수 있음
다른 테이블의 내용을 복사해서 내 테이블에 넣는 방법 or 그 반대=데이터를 복사하는 방법
서브쿼리를 사용. 'CTAS'라고도 함
CREATE TABLE copy_emp
AS SELECT *
FROM employees = 여기까지 하면 구조와 data 전부를 복사함
WHERE 1=2 = 이 조건을 주면 맞는 데이터가 전혀 없기 때문에 구조만 복사됨
- Insert에 테이블 대신 서브쿼리 이용 예제
INSERT INTO
(SELECT employee_id, last_name,
email, hire_date, job_id, salary,
department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
* UPDATE
1. UPDATE 형식: UPDATE SET WHERE
- UPDATE table
SET column = value
WHERE condition;
WHERE 절을 안쓰면 전부를 바꿀수 있음 조심
- 여러 값을 서브쿼리를 이용해 바꾸고자 할때.
update emp
set job_id=(select job_id from emp where emp_id=205),
sal=(select sal from emp where emp_id=205)
where emp_id=114;
* DELETE
1. DELETE 형식: DELETE WHERE
- DELETE table
WHERE condition;
예제1) 1개만 지워진다
DELETE FROM departments
WHERE department_name = 'Finance';
예제2) 모두 지워진다- 조심
DELETE FROM copy_emp;
- 다른 테이블을 이용한 열 삭제 예제
DELETE FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE department_name
LIKE '%Public%');
그러나 아마 연관된 레코드가 있다며 무결성 제약 오류가 날 가능성이 크다.(외래키)
2012년 3월 25일 일요일
join 문제풀이
6번문제 5-33p
select e.dep_id department, e.last_name employee, m.last_name colleague
from emp e join emp m
on (e.dep_id=m.dep_id)
and (e.last_name<>m.last_name)
order by e.dep_id, e.last_name, m.last_name
and(e.last_name<>m.last_name)이 중요
문제에 힌트가 너무 없고 결과를 보고 추리를 해야하기 때문에 찾아봤음.. 내 사고가 딸리나
7번문제 5-34p
select e.last_name, e.job_id, d.dep_name, e.sal, j.gra
from emp e join dep d
on (e.dep_id=d.dep_id)
join job_grades j
on e.sal between j.low_sal and j.high_sal
select e.dep_id department, e.last_name employee, m.last_name colleague
from emp e join emp m
on (e.dep_id=m.dep_id)
and (e.last_name<>m.last_name)
order by e.dep_id, e.last_name, m.last_name
and(e.last_name<>m.last_name)이 중요
문제에 힌트가 너무 없고 결과를 보고 추리를 해야하기 때문에 찾아봤음.. 내 사고가 딸리나
7번문제 5-34p
select e.last_name, e.job_id, d.dep_name, e.sal, j.gra
from emp e join dep d
on (e.dep_id=d.dep_id)
join job_grades j
on e.sal between j.low_sal and j.high_sal
2012년 3월 23일 금요일
salary 1000당 * 표시 나오게 하기
10g sql fundamental1_sg1 3-67p의 문제..
이건 교재에도 나오지 않은 내용은데 어떻게 풀라는건지
원하는건 last_name의 8자와 salary 1000당 *하나를 입력하는 것이다.
select substr(last_name,1,8)||' '||lpad(' ', trunc(salary/1000+1),'*')
from employees
order by salary desc;
핵심은 lpad후 ' '을 써서 아무것도 내용을 쓰지 않는 것
좀더 매끄럽게 할 수도 있을거 같은데 나중에 다듬어바야지
이건 교재에도 나오지 않은 내용은데 어떻게 풀라는건지
원하는건 last_name의 8자와 salary 1000당 *하나를 입력하는 것이다.
select substr(last_name,1,8)||' '||lpad(' ', trunc(salary/1000+1),'*')
from employees
order by salary desc;
핵심은 lpad후 ' '을 써서 아무것도 내용을 쓰지 않는 것
좀더 매끄럽게 할 수도 있을거 같은데 나중에 다듬어바야지
nvl2를 이용한 commission 조회
원하는건 commission_pct가 null 값이라면 No commission이란 문자를 리턴하고
null값이 아니라면 그대로 commission_pct를 리턴해주려고 한다.
그래서 간단히 아래와 같이 생각했으나
select last_name,
NVL2(commission_pct, commission_pct, 'No Commission')
from employees;
NVL2(commission_pct, commission_pct, 'No Commission')
*
ERROR at line 2:
ORA-01722: invalid number
에러가 뜬다
좀 찾아보니 nvl2건 coalecse건 리턴하는 값은 둘다 같은 타입이어야 하는 결론이 나왔다.
그래서 아래처럼 바꾸어서 해결.
select last_name,
NVL2(commission_pct, to_char(commission_pct), 'No Commission')
from employees;
null값이 아니라면 그대로 commission_pct를 리턴해주려고 한다.
그래서 간단히 아래와 같이 생각했으나
select last_name,
NVL2(commission_pct, commission_pct, 'No Commission')
from employees;
NVL2(commission_pct, commission_pct, 'No Commission')
*
ERROR at line 2:
ORA-01722: invalid number
에러가 뜬다
좀 찾아보니 nvl2건 coalecse건 리턴하는 값은 둘다 같은 타입이어야 하는 결론이 나왔다.
그래서 아래처럼 바꾸어서 해결.
select last_name,
NVL2(commission_pct, to_char(commission_pct), 'No Commission')
from employees;
요일별 정렬 monday 맨앞으로 오게하기
요일별로 정렬할때 monday가 맨앞으로 오게하기
select last_name, hire_date, to_char(hire_date,'DAY') DAY
from employees
order by to_char(hire_date-1,'D');
D=날짜를 숫자로 표현
1=sunday, 2=monday
이므로 -1을 줘서 monday를 1로 만듬
select last_name, hire_date, to_char(hire_date,'DAY') DAY
from employees
order by to_char(hire_date-1,'D');
D=날짜를 숫자로 표현
1=sunday, 2=monday
이므로 -1을 줘서 monday를 1로 만듬
2012년 3월 20일 화요일
OLTP,OLAP,DW 정의
OLTP: OnLine Transaction Processing
Batch 와 반대되는 개념으로 실시간으로 db의 데이터를 트랜잭션 단위로 갱신/조회하는 처리방식. 은행, 증권사 등에서 씀. 기존과 달리 다수의 client가 거의 동시에 이용할수 있도록 송수신자료를 트랜잭션단위로 압축한것이 특징.
DW: Data Warehouse
수년간 발생한 데이터를 모아서 주제별로 합쳐 분석할 수 있게 하는 통합시스템.
예) 운영데이터, 분산데이터, 시장데이터를 추출하여 DW를 구축하고 그걸 DSS나 OLAP로 분석
※Data Mart: DW의 하위단위라고 볼 수 있으며, DW는 중앙집중식 데이터 집합체의 개념을 가지나, data mart는 데이터 저장소의 역할을 하고 특정 목적을 위해 쉬운 접근성과 사용성을 가진다. DW는 기존 데이터를 어떻게 수집/분석하고 어떻게 재사용할 것인가에 초점을 맞춤
OLAP:OnLine Analytical Processing
위의 DW에서 데이터를 분석해서 의미있는 형태로 만들기 위한 과정및 도구. 의사결정 지원 시스템의 하나.
※ 의사결정 지원 시스템(DSS, Decision Support System)
단순히 정보를 수집, 저장, 분배하기 위한 시스템을 넘어서 사용자들이 기업의 의사결정을 쉽게 내릴 수 있도록 사업 자료를 분석해주는 역할을 하는 컴퓨터 응용 프로그램이다.
Batch Processing
작업을 몰아두었다가 한번에 처리하는 시스템. 예:선거투표결과 추출, 게임 이벤트 아이템 일괄 지급 등
Batch 와 반대되는 개념으로 실시간으로 db의 데이터를 트랜잭션 단위로 갱신/조회하는 처리방식. 은행, 증권사 등에서 씀. 기존과 달리 다수의 client가 거의 동시에 이용할수 있도록 송수신자료를 트랜잭션단위로 압축한것이 특징.
DW: Data Warehouse
수년간 발생한 데이터를 모아서 주제별로 합쳐 분석할 수 있게 하는 통합시스템.
예) 운영데이터, 분산데이터, 시장데이터를 추출하여 DW를 구축하고 그걸 DSS나 OLAP로 분석
※Data Mart: DW의 하위단위라고 볼 수 있으며, DW는 중앙집중식 데이터 집합체의 개념을 가지나, data mart는 데이터 저장소의 역할을 하고 특정 목적을 위해 쉬운 접근성과 사용성을 가진다. DW는 기존 데이터를 어떻게 수집/분석하고 어떻게 재사용할 것인가에 초점을 맞춤
OLAP:OnLine Analytical Processing
위의 DW에서 데이터를 분석해서 의미있는 형태로 만들기 위한 과정및 도구. 의사결정 지원 시스템의 하나.
※ 의사결정 지원 시스템(DSS, Decision Support System)
단순히 정보를 수집, 저장, 분배하기 위한 시스템을 넘어서 사용자들이 기업의 의사결정을 쉽게 내릴 수 있도록 사업 자료를 분석해주는 역할을 하는 컴퓨터 응용 프로그램이다.
Batch Processing
작업을 몰아두었다가 한번에 처리하는 시스템. 예:선거투표결과 추출, 게임 이벤트 아이템 일괄 지급 등
2012년 3월 15일 목요일
OEL5.7에 oracle 9i R2를 깔면서 내린 결론
9i R2를 운용하려면 절대 rhel5 이상에 깔면 안된다!
os와 java의 상성이 안좋다. 어찌저찌 억지로 설치할순 있으나 그래도 문제점이 많이 남는다.패치시에 dbua마저 제대로 동작하지 않는다.
추후에 어떤 에러들이 나는지 기록할 예정. 허참 별의별 에러들이.
oracle 9i를 설치하려면 rhel3나 4를 추천한다.
os와 java의 상성이 안좋다. 어찌저찌 억지로 설치할순 있으나 그래도 문제점이 많이 남는다.패치시에 dbua마저 제대로 동작하지 않는다.
추후에 어떤 에러들이 나는지 기록할 예정. 허참 별의별 에러들이.
oracle 9i를 설치하려면 rhel3나 4를 추천한다.
2012년 3월 13일 화요일
띄엄띄엄 책 중요 포인트 요약중
2장.
*실무에서 가장 많이 사용되는 설치옵션- oracle database 10g, Enterprise edition 옵션중 파티셔닝,디벨롭킷.
*설치중 링크 에러시 로그 확인하고 조치를 취한 뒤 $ORACLE_HOME/bin/relink all 로 링크 재실행.
*데이터베이스 필수파일= 데이터, 컨트롤, 리두로그
*db 생성시에는 startup nomount.
*리두로그는 최소 2개의 그룹, 그룹당 1개의 멤버
*character set은 보통 KO16WIN949 or KO16KSC5601
*catalog.sql = 데이터 딕셔너리뷰 생성, catproc.sql = 필요패키지 생성?
*ASM=10g부터 생김
*RAW 장치=파일시스템을 만들기 전 단계인 RAW device 를 사용해 데이터파일로 사용. 많이 사용안됨, RAC 구성할땐 RAW로밖에 안됨. 여러 시스템에서 하나의 db에 접근해야 하는데 이건 RAW밖에 안됐음. 10g부터는 ASM도 가능하게 됨.
*오라클넷 사용시 가장 자주 쓰는게 로컬이름방식=Tnsnames.ora파일(클라이언트에 있음) 등록된 db정보 이용 접속(listener.ora 파일은 서버측)
3장.
요약불가, 팁정도만 기록함.
*Granule 단위-sga_max_size가 128M이하면 4M, 초과하면 16M. 예를 들어 sga_max_size가 130인 상태에서 데이터버퍼캐쉬를 32에서 40으로 늘리려고 해도 32+16인 48로 설정됨.
*공유풀 예약공간-실무에선 잘 안씀,보통은 기본값
*데이터버퍼캐쉬-성능을 위해 SGA에서 보통 제일 크게 잡아줌.
*데이터블록크기-db가 대용량화되어감에 따라 크게 설정하는 것이 일반적
*다중데이터버퍼캐쉬-테이블 수가 많으면 하나하나 적용하기 힘들어서 잘 안씀.
*리두로그 크기-1~10M 적당
*대형풀-필수는 아니지만 공유풀 부하 감소를 위해 사용하는것이 좋음
*ASMM(Automatic Shared Memory Management)-10g부터 생긴 기능. 공유풀,데이터버퍼,대형/자바풀 자동 조절.주의할 점은 최소값을 설정해서 메모리크기가 작게 설정되는걸 방지하는 것.
MMAN이 관리함(Memory MANager)
*실무에서 가장 많이 사용되는 설치옵션- oracle database 10g, Enterprise edition 옵션중 파티셔닝,디벨롭킷.
*설치중 링크 에러시 로그 확인하고 조치를 취한 뒤 $ORACLE_HOME/bin/relink all 로 링크 재실행.
*데이터베이스 필수파일= 데이터, 컨트롤, 리두로그
*db 생성시에는 startup nomount.
*리두로그는 최소 2개의 그룹, 그룹당 1개의 멤버
*character set은 보통 KO16WIN949 or KO16KSC5601
*catalog.sql = 데이터 딕셔너리뷰 생성, catproc.sql = 필요패키지 생성?
*ASM=10g부터 생김
*RAW 장치=파일시스템을 만들기 전 단계인 RAW device 를 사용해 데이터파일로 사용. 많이 사용안됨, RAC 구성할땐 RAW로밖에 안됨. 여러 시스템에서 하나의 db에 접근해야 하는데 이건 RAW밖에 안됐음. 10g부터는 ASM도 가능하게 됨.
*오라클넷 사용시 가장 자주 쓰는게 로컬이름방식=Tnsnames.ora파일(클라이언트에 있음) 등록된 db정보 이용 접속(listener.ora 파일은 서버측)
3장.
요약불가, 팁정도만 기록함.
*Granule 단위-sga_max_size가 128M이하면 4M, 초과하면 16M. 예를 들어 sga_max_size가 130인 상태에서 데이터버퍼캐쉬를 32에서 40으로 늘리려고 해도 32+16인 48로 설정됨.
*공유풀 예약공간-실무에선 잘 안씀,보통은 기본값
*데이터버퍼캐쉬-성능을 위해 SGA에서 보통 제일 크게 잡아줌.
*데이터블록크기-db가 대용량화되어감에 따라 크게 설정하는 것이 일반적
*다중데이터버퍼캐쉬-테이블 수가 많으면 하나하나 적용하기 힘들어서 잘 안씀.
*리두로그 크기-1~10M 적당
*대형풀-필수는 아니지만 공유풀 부하 감소를 위해 사용하는것이 좋음
*ASMM(Automatic Shared Memory Management)-10g부터 생긴 기능. 공유풀,데이터버퍼,대형/자바풀 자동 조절.주의할 점은 최소값을 설정해서 메모리크기가 작게 설정되는걸 방지하는 것.
MMAN이 관리함(Memory MANager)
피드 구독하기:
글 (Atom)