dba_data_files, dba_free_space 뷰 사용
select d.tn, round(total/1024/1024) total_mb,
round(free/1024/1024) free_mb,
to_char(round(free/total*100,1), '99.9')||'%' rate
from (select tablespace_name tn, sum(bytes) total
from dba_data_files
group by tablespace_name) d,
(select tablespace_name tn, sum(bytes) free
from dba_free_space
group by tablespace_name) f
where d.tn=f.tn;
2012년 5월 30일 수요일
2012년 5월 29일 화요일
2012년 5월 17일 목요일
Hidden Parameter 조회
select a.ksppinm, b.ksppstvl
from x$ksppi a, x$ksppsv b
where a.indx=b.indx
and ksppinm like '_optimizer_cost_model';
x$ksppi 뷰의 ksppinm 컬럼=실제 파라미터 이름
ksppdesc=디스크립션정보
x$ksppsv 뷰의 ksppstvl 컬럼=해당 파라미터 값
두 뷰 공통적 컬럼=indx
from x$ksppi a, x$ksppsv b
where a.indx=b.indx
and ksppinm like '_optimizer_cost_model';
x$ksppi 뷰의 ksppinm 컬럼=실제 파라미터 이름
ksppdesc=디스크립션정보
x$ksppsv 뷰의 ksppstvl 컬럼=해당 파라미터 값
두 뷰 공통적 컬럼=indx
2012년 4월 10일 화요일
admin ws1 다섯째날
* 권한: 특정 sql문을 실행하거나 다른 유저의 객체에 접근할수 있는 자격.
- system 권한: dba가 user에게 주는 권한으로. any라는 권한을 주는 상황이 많다. with admin option을 사용할 수 있으며 revoke시 해당 grantee에게 다시 권한을 할당받은 grantee의 권한은 제거되지 않아 보안상 문제가 생긴다.
- object 권한: owner가 user에게 주는 권한으로 with grant option 사용 가능하며 revoke시 해당 grantor에게 권한을 받은 grantee들의 권한도 같이 제거된다.
- select * from dba_tab_privs;
* sysdba와 sysoper 권한: sysdba는 superuser라고 볼수 있으나 sysoper는 db는 삭제할 수는 없고 다른 user data를 볼수도 없다.
* role
- role 안에 role을 넣을수도 있다.
- 인증을 통해 role 부여도 가능하다.
- role은 객체가 아니며 owner도 없고 어떤 스키마에도 속하지 않는다.
- 일반적으론 default role을 사용한다.
- set role role이름 으로 변경 가능.
* predefined role
- connect: create session
- resource: create cluster, create indextype, create operator, create procedure, create sequence, create table, create trigger, create type
- resource는 unlimited tablespace 권한도 포함되어있다=quota가 먹지 않는다.=system tablespace도 사용 가능하다
- scheduler_admin: create any job, create external job, create job, execute any class, execute any program, manage scheduler
- dba: 대부분의 시스템 권한
- select_catalog_role: data dictionary에 대해 select만 가능하도록 부여할때 사용.
- o7_dic_a: 제일 먼저 나오는 parameter이며 반드시 false여야 함. 이걸 true로 할 경우 모든 일반 user들이 다 dictinary를 조회 가능
- select any table: 모든 스키마를 볼수 있지만 dictionary는 못봄
- select * from role_sys_privs;
* profile: 한계집합이라고도 한다. profile은 user가 하나씩 사용 가능하다.
- resource: resource_limit 파라메터가 true되어야만 사용 가능하다. 기본값 false. 즉 resource는 옵션
- cpu per session: 1000으로 설정하면 10초로 설정됨. 세션당 10초를 넘어가는 경우 rollback+ logoff
- cpu per call: 하나의 call이 한계값을 넘으면 rollback
- network / memory
- connect time
- idle time
- concurrent session: 한 client 측에서 사용가능한 동시 세션수로 실무에선 3개 주로 사용
- private sga: 정렬, 비트맵 병합등에 사용되는 공간의 양 제한. shared server 사용하는 경우만 적용
- disk I/O: read per call, read per session 사용가능
- password 보안
- password history: 기존 pw 기록을 보관하며 조건을 제한함. 볼수는 없음
- password_reuse_time: 주어진 일수동안 암호 재사용 불가
- password_reuse_max: 이전 패스워드를 사용하기 위한 암호 변경 횟수
※위 두개의 파라메터는 함께 사용 불가. 하나를 수정하면 다른 하나는 unlimited여야함
- password 복잡성
- password_verify_function을 verify_function로 지정함. verify_function은 $ORACLE_HOME/rdbms/admin/utlpwdmg.sql 스크립트로 생성하는 함수
- verify_function 주건: 최소길이 4, username과 동일할수 없음, 한개문자/한개숫자/한개특수문자 포함해야함, 이전 암호와 최소한 3자이상 달라야함.
- password aging and expire
- password_life_time: 암호만료수명. 일단위 지정
- password_grace_time: 만료후 유예기간
※위 파라메터로 sys, sysman, dbsnmp 계정 lock이 되지 안도록 주의
- password lock
- password_login_attempts: 해당 로그인 횟수 실패시 lock
- password_lock_time: lock시 lock되는 날짜
* default profile과 일반 profile
- user create시 명시하지 않으면 일반적으로 default profile을 사용하게 되며 도중에 다른 profile을 사용하게 되면 default profile은 해제가 된다. 다시 그 profile을 해제하면 default profile이 적용된다.
- system 권한: dba가 user에게 주는 권한으로. any라는 권한을 주는 상황이 많다. with admin option을 사용할 수 있으며 revoke시 해당 grantee에게 다시 권한을 할당받은 grantee의 권한은 제거되지 않아 보안상 문제가 생긴다.
- object 권한: owner가 user에게 주는 권한으로 with grant option 사용 가능하며 revoke시 해당 grantor에게 권한을 받은 grantee들의 권한도 같이 제거된다.
- select * from dba_tab_privs;
* sysdba와 sysoper 권한: sysdba는 superuser라고 볼수 있으나 sysoper는 db는 삭제할 수는 없고 다른 user data를 볼수도 없다.
* role
- role 안에 role을 넣을수도 있다.
- 인증을 통해 role 부여도 가능하다.
- role은 객체가 아니며 owner도 없고 어떤 스키마에도 속하지 않는다.
- 일반적으론 default role을 사용한다.
- set role role이름 으로 변경 가능.
* predefined role
- connect: create session
- resource: create cluster, create indextype, create operator, create procedure, create sequence, create table, create trigger, create type
- resource는 unlimited tablespace 권한도 포함되어있다=quota가 먹지 않는다.=system tablespace도 사용 가능하다
- scheduler_admin: create any job, create external job, create job, execute any class, execute any program, manage scheduler
- dba: 대부분의 시스템 권한
- select_catalog_role: data dictionary에 대해 select만 가능하도록 부여할때 사용.
- o7_dic_a: 제일 먼저 나오는 parameter이며 반드시 false여야 함. 이걸 true로 할 경우 모든 일반 user들이 다 dictinary를 조회 가능
- select any table: 모든 스키마를 볼수 있지만 dictionary는 못봄
- select * from role_sys_privs;
* profile: 한계집합이라고도 한다. profile은 user가 하나씩 사용 가능하다.
- resource: resource_limit 파라메터가 true되어야만 사용 가능하다. 기본값 false. 즉 resource는 옵션
- cpu per session: 1000으로 설정하면 10초로 설정됨. 세션당 10초를 넘어가는 경우 rollback+ logoff
- cpu per call: 하나의 call이 한계값을 넘으면 rollback
- network / memory
- connect time
- idle time
- concurrent session: 한 client 측에서 사용가능한 동시 세션수로 실무에선 3개 주로 사용
- private sga: 정렬, 비트맵 병합등에 사용되는 공간의 양 제한. shared server 사용하는 경우만 적용
- disk I/O: read per call, read per session 사용가능
- password 보안
- password history: 기존 pw 기록을 보관하며 조건을 제한함. 볼수는 없음
- password_reuse_time: 주어진 일수동안 암호 재사용 불가
- password_reuse_max: 이전 패스워드를 사용하기 위한 암호 변경 횟수
※위 두개의 파라메터는 함께 사용 불가. 하나를 수정하면 다른 하나는 unlimited여야함
- password 복잡성
- password_verify_function을 verify_function로 지정함. verify_function은 $ORACLE_HOME/rdbms/admin/utlpwdmg.sql 스크립트로 생성하는 함수
- verify_function 주건: 최소길이 4, username과 동일할수 없음, 한개문자/한개숫자/한개특수문자 포함해야함, 이전 암호와 최소한 3자이상 달라야함.
- password aging and expire
- password_life_time: 암호만료수명. 일단위 지정
- password_grace_time: 만료후 유예기간
※위 파라메터로 sys, sysman, dbsnmp 계정 lock이 되지 안도록 주의
- password lock
- password_login_attempts: 해당 로그인 횟수 실패시 lock
- password_lock_time: lock시 lock되는 날짜
* default profile과 일반 profile
- user create시 명시하지 않으면 일반적으로 default profile을 사용하게 되며 도중에 다른 profile을 사용하게 되면 default profile은 해제가 된다. 다시 그 profile을 해제하면 default profile이 적용된다.
2012년 4월 9일 월요일
admin ws1 넷째날
* 공간 관점에서의 table space
- t/s를 쪼개면 segment, extent, db block
- 공간을 관리한다는 이야기는 segment, extent, block을 어떻게 관리할 것인가의 이야기
* t/s 만들때 type
- permanent: 일반적인 data file
- temporary: 정렬할때만 사용
- undo
* extent allovcation: extent
- extent 사이즈를 지정하는 방식
- auto: 서버가 필요한만큼 지정. extent 사이즈가 다 상이할 수 있음. 단편화 현상이 많아짐.
- uniform: 모든 extent 사이즈를 dba가 지정. 기본은 1M. 사이즈가 동일하기에 성능상 이점 있음.
* segment space management
- LMT를 선택하면 선택할 수 있는 기능으로 segment 관리 방법 설정
- auto: bitmap 방식. ASSM(Automatic Segment Space Management)
- manual: freelist를 조사함. 이전버젼과 호환성 위해서만 존재, auto 권장
* enable logging: t/s를 만들며 생기는 작업에 대한 로그를 남김. 보통 no
* predefined tablespace
- system: data dictionary 저장됨. SYS 스킴가 사용. user가 여길 사용하게 하면 hang 걸릴수 있음. 절대 r/o로 변경하면 안됨.
- sysaux: 10g부터 도입. system t/s에 보관할 수 잇는 사이즈를 넘는 정보를 저장.
- temp: index 생성이나 정렬을 위해 사용
- undotbs1
- users: 10g부터 default table space.
- example: sample schema
* segment 종류
- table: data segment
- index segment
- undo segment
- temp segment
- cache(boot strap) segment: system t/s에 존재하며 permanent type이나 데이터는 아닌 data dictionary이기에 따로 이름을 부르기 위해 cache segment라고 부른다고 생각하면 됨.
* offline 옵션
- normal: 일반적인 offline. t/s의 모든 data file에 오류조건이 없을 경우 offline됨. checkpoint 발생하므로 모든 데이터가 디스크에 기록됨.
- temporary: 오류조건이 있어도 임시로 t/s를 오프라인함. checkpoint 발생.
- immediate: checkpoint를 발생시키지 않고 즉시 offline으로 변경함. 단 noarchivelog 모드인 경우 불가. online으로 돌리려면 media recovery 필요.
- for recover: 이전 버젼 호환성위해서만 사용.
* t/s 삭제
- t/s를 삭제하면 datafile과의 연결을 끊기만 한다고 생각하면 된다. 옵션을 추가해야 데이터파일도 삭제할 수 있다.
- 사용자가 DML작업중인 경우 drop할 수 없기에 offline 후 drop을 권장한다.
* t/s 확인
- tablespace: dba_tablespace, v$tablespace
- datafile: dba_datafile, v$datafile
- temp file: dba_temp_file, v$tempfile
* db사이즈가 커지는 케이스
- t/s 생성
-기존t/s에 data file을 추가
-기본 datafile을 resizing으로 추가
-자동 확장기능 사용
* 계정에 속한 정보들
- user이름
- 인증방식
- default t/s: 생성시 따로 명시 안했으면 system defined default t/s 지정됨(USERS)
- 9i까지는 system t/s가 sys defined default t/s여서 저장해서 문제가 많았다.
- 따로 지정방법: creater user kim identified by kim default tablespace A;
- temp t/s: 생성시 따로 명시안했으면 system defined temp t/s 지정됨
- user profile
- consumer group: 나중에 resource manager에서 나옴
- lock state
* temporary t/s
- 정렬을 위한 t/s
- 정렬을 일으키는 작업: index 생성, order by, group by, union, minus 등
※튜닝에서 정렬을 없애는 것도 하나의 이슈
- pga에서 sort area가 있는데 정렬을 할때 이 메모리가 부족하면 temp t/s를 쓰게 된다.
* 인증방법
- password 인증: dictionary 인증 or db인증이라고도 함
- user가 os의 인증을 받았다고 해도 db에 접속할경우 db의 인증을 다시한번 해야함.
- remote로 접속할때 pw인증을 위해 pw 파일이 필요함.
- external 인증(os인증): OS의 kim user를 db에 등록해두면 db에 접근할때 sqlplus / 만으로 로그인 가능.
- local 인증시는 큰 이슈가 없으나 remote로 os인증하여 로그인하면 보안에 허점 발생
- OS_AUTHENTT_PREFIX=OPS$ -> create user OPS$kim identified by externally 로 구현
※DBA는 반드시 OS 파일 생성이나 삭제 권한을 가져야 한다.=시스템 admin과 자주 이것때문에 싸움
- t/s를 쪼개면 segment, extent, db block
- 공간을 관리한다는 이야기는 segment, extent, block을 어떻게 관리할 것인가의 이야기
* t/s 만들때 type
- permanent: 일반적인 data file
- temporary: 정렬할때만 사용
- undo
* extent allovcation: extent
- extent 사이즈를 지정하는 방식
- auto: 서버가 필요한만큼 지정. extent 사이즈가 다 상이할 수 있음. 단편화 현상이 많아짐.
- uniform: 모든 extent 사이즈를 dba가 지정. 기본은 1M. 사이즈가 동일하기에 성능상 이점 있음.
* segment space management
- LMT를 선택하면 선택할 수 있는 기능으로 segment 관리 방법 설정
- auto: bitmap 방식. ASSM(Automatic Segment Space Management)
- manual: freelist를 조사함. 이전버젼과 호환성 위해서만 존재, auto 권장
* enable logging: t/s를 만들며 생기는 작업에 대한 로그를 남김. 보통 no
* predefined tablespace
- system: data dictionary 저장됨. SYS 스킴가 사용. user가 여길 사용하게 하면 hang 걸릴수 있음. 절대 r/o로 변경하면 안됨.
- sysaux: 10g부터 도입. system t/s에 보관할 수 잇는 사이즈를 넘는 정보를 저장.
- temp: index 생성이나 정렬을 위해 사용
- undotbs1
- users: 10g부터 default table space.
- example: sample schema
* segment 종류
- table: data segment
- index segment
- undo segment
- temp segment
- cache(boot strap) segment: system t/s에 존재하며 permanent type이나 데이터는 아닌 data dictionary이기에 따로 이름을 부르기 위해 cache segment라고 부른다고 생각하면 됨.
* offline 옵션
- normal: 일반적인 offline. t/s의 모든 data file에 오류조건이 없을 경우 offline됨. checkpoint 발생하므로 모든 데이터가 디스크에 기록됨.
- temporary: 오류조건이 있어도 임시로 t/s를 오프라인함. checkpoint 발생.
- immediate: checkpoint를 발생시키지 않고 즉시 offline으로 변경함. 단 noarchivelog 모드인 경우 불가. online으로 돌리려면 media recovery 필요.
- for recover: 이전 버젼 호환성위해서만 사용.
* t/s 삭제
- t/s를 삭제하면 datafile과의 연결을 끊기만 한다고 생각하면 된다. 옵션을 추가해야 데이터파일도 삭제할 수 있다.
- 사용자가 DML작업중인 경우 drop할 수 없기에 offline 후 drop을 권장한다.
* t/s 확인
- tablespace: dba_tablespace, v$tablespace
- datafile: dba_datafile, v$datafile
- temp file: dba_temp_file, v$tempfile
* db사이즈가 커지는 케이스
- t/s 생성
-기존t/s에 data file을 추가
-기본 datafile을 resizing으로 추가
-자동 확장기능 사용
* 계정에 속한 정보들
- user이름
- 인증방식
- default t/s: 생성시 따로 명시 안했으면 system defined default t/s 지정됨(USERS)
- 9i까지는 system t/s가 sys defined default t/s여서 저장해서 문제가 많았다.
- 따로 지정방법: creater user kim identified by kim default tablespace A;
- temp t/s: 생성시 따로 명시안했으면 system defined temp t/s 지정됨
- user profile
- consumer group: 나중에 resource manager에서 나옴
- lock state
* temporary t/s
- 정렬을 위한 t/s
- 정렬을 일으키는 작업: index 생성, order by, group by, union, minus 등
※튜닝에서 정렬을 없애는 것도 하나의 이슈
- pga에서 sort area가 있는데 정렬을 할때 이 메모리가 부족하면 temp t/s를 쓰게 된다.
* 인증방법
- password 인증: dictionary 인증 or db인증이라고도 함
- user가 os의 인증을 받았다고 해도 db에 접속할경우 db의 인증을 다시한번 해야함.
- remote로 접속할때 pw인증을 위해 pw 파일이 필요함.
- external 인증(os인증): OS의 kim user를 db에 등록해두면 db에 접근할때 sqlplus / 만으로 로그인 가능.
- local 인증시는 큰 이슈가 없으나 remote로 os인증하여 로그인하면 보안에 허점 발생
- OS_AUTHENTT_PREFIX=OPS$ -> create user OPS$kim identified by externally 로 구현
※DBA는 반드시 OS 파일 생성이나 삭제 권한을 가져야 한다.=시스템 admin과 자주 이것때문에 싸움
2012년 4월 5일 목요일
admin ws1 셋째날
* Parameter: 성능과 밀접한 관계
- basic parameter 32개와 그 외 advanced parameter 가 있음.
- 몇몇 항목들 예시
①control_file: c 파일의 위치, 이름. show parameter control_file 로 볼수 있음. control file이 담긴 디스크의 장애 등을 대비해 멀티플렉싱과 미러링을 권장함. 최대 파일 갯수는 8개
②db_block_size: 1k~64k까지 가능하다고 이론상 하지만 실제론 2k~32k밖에 안씀.
③db_cache_size: db_buffer_cache 총사이즈(내 instance는 0으로 나오네), 기본값은 48M
④db_nk_cache_size: 기본 블록사이즈에 해당하지 않는 data file을 불러들이는 경우가 있는데 이 경우 db_nk_cache_size를 사용하게 됨. 만약 기본 블록사이즈를 8k로 정한 경우 2,4,6,16,32k 단위의 datafile은 여기서 불러들이게 된다.
⑤db_file_multiblock_read_count: data file을 불러들이러 disk에 접근할때 한번에 여러개의 블록을 동시에 읽기 위한 카운트로 기본값은 8개.
⑥db_files: db에서 열수 있는 최대 data file 개수.기본 200개로(os따라 다름) 최대 maxdatafiles(os에 따라 다름)까지 가능.
⑦pga_aggregate_target: PGA의 크기 설정. 최소 10M, 최대 4096G. 기본값은 10M이거나 SGA의 20%중 큰 값(내건 90M, sga_targer은 262M. ???262M x 0.2: 52M인데?)
⑧process: 오라클 서버에 동시 연결할 수 있는 OS 사용자들의 최대 수.
⑨shared_pool_size: sps의 사이즈. 기본값: 16m
⑩undo_management: undo 관리 방법으로 보통 auto 사용.
* alert log
- 위치: background_dump_dest 파라메터 위치의 aleart_<sid>.log 파일
* dynamic performance view: x$를 기반으로 만든 v$ 뷰, db 메모리에 직접 액세스해 지금 db의 상태를 보여준다.
- v$ 가 붙으면 지금 현재 상태를 보여준다고 알면 된다.
- v$의 종류는 v$fixed_table에 다 있음.
* data block
- 행의 내용이 너무 커서 여러개의 블록에 행이 나누어져 들어갈 수도 있음. 이 경우를 chaining block 이라 함.
- block header: 세그먼트 유형(테이블, 인덱스등), 데이터블록 주소, table directory(어느 테이블의 내용인가), row directory(행이 몇개 드러있나), transaction slot이 있음.
- transaction slot: dml 작업을 진행하고 잎다면 block에 접근해야 하는데 이때 transaction slot이란 티켓을 얻어야 접근이 가능하다.
①block space parameter로 수정 가능
②initrans: 최소 티켓, 기본 값은 테이블의 경우 1, 인덱스는 2
③maxtrans: 255
- free space: dml이 자주 발생하면 단편화가 생기는데 오라클 서버가 알아서 병합작업을 진행함.
* OMF(Oracle Managed file)
- 반대는 UMF(User Managed file)
- db_create_file_dest 파라메터만 수정해주면 알아서 파일이름, 사이즈를 정해서 생성한다.
* 테이블 스페이스 관리
- table space를 쪼개 들어가면 extent 라는 공간으로 쪼개지는데 한 extent에 insert가 많이 일어나서 확장이 필요하다면 공간할당을 해야하는데, extent 공간 할당의 방법이 두가지로 나누어진다.
① LMT: Locally management table space. 일반적으로 이걸 쓴다. 표준화까지 됨.
- table space 자신이 공간에 대한 정보를 bitmap을 통해 관리한다.
- bitmap(전광판이라 생각하면 됨)으로 인접한 사용 가능 extent를 미리 파악해둔다.
②DMT: Dictionary management table space: 이전 버젼과 호환성때문에만 지원한다(8i 이전)
- data dictionary에서 extent를 관리한다.
- free extent에 대한 정보가 DIC에 저장되어 있는데(예: dba_extens) tablespace를 위한 extent 요구가 많아지면 경합이 발생한다.
- freelist를 계속 유지하고 있기에 extent들에 대한 정보를 계속 갱신해야 한다=성능
- basic parameter 32개와 그 외 advanced parameter 가 있음.
- 몇몇 항목들 예시
①control_file: c 파일의 위치, 이름. show parameter control_file 로 볼수 있음. control file이 담긴 디스크의 장애 등을 대비해 멀티플렉싱과 미러링을 권장함. 최대 파일 갯수는 8개
②db_block_size: 1k~64k까지 가능하다고 이론상 하지만 실제론 2k~32k밖에 안씀.
③db_cache_size: db_buffer_cache 총사이즈(내 instance는 0으로 나오네), 기본값은 48M
④db_nk_cache_size: 기본 블록사이즈에 해당하지 않는 data file을 불러들이는 경우가 있는데 이 경우 db_nk_cache_size를 사용하게 됨. 만약 기본 블록사이즈를 8k로 정한 경우 2,4,6,16,32k 단위의 datafile은 여기서 불러들이게 된다.
⑤db_file_multiblock_read_count: data file을 불러들이러 disk에 접근할때 한번에 여러개의 블록을 동시에 읽기 위한 카운트로 기본값은 8개.
⑥db_files: db에서 열수 있는 최대 data file 개수.기본 200개로(os따라 다름) 최대 maxdatafiles(os에 따라 다름)까지 가능.
⑦pga_aggregate_target: PGA의 크기 설정. 최소 10M, 최대 4096G. 기본값은 10M이거나 SGA의 20%중 큰 값(내건 90M, sga_targer은 262M. ???262M x 0.2: 52M인데?)
⑧process: 오라클 서버에 동시 연결할 수 있는 OS 사용자들의 최대 수.
⑨shared_pool_size: sps의 사이즈. 기본값: 16m
⑩undo_management: undo 관리 방법으로 보통 auto 사용.
* alert log
- 위치: background_dump_dest 파라메터 위치의 aleart_<sid>.log 파일
* dynamic performance view: x$를 기반으로 만든 v$ 뷰, db 메모리에 직접 액세스해 지금 db의 상태를 보여준다.
- v$ 가 붙으면 지금 현재 상태를 보여준다고 알면 된다.
- v$의 종류는 v$fixed_table에 다 있음.
* data block
- 행의 내용이 너무 커서 여러개의 블록에 행이 나누어져 들어갈 수도 있음. 이 경우를 chaining block 이라 함.
- block header: 세그먼트 유형(테이블, 인덱스등), 데이터블록 주소, table directory(어느 테이블의 내용인가), row directory(행이 몇개 드러있나), transaction slot이 있음.
- transaction slot: dml 작업을 진행하고 잎다면 block에 접근해야 하는데 이때 transaction slot이란 티켓을 얻어야 접근이 가능하다.
①block space parameter로 수정 가능
②initrans: 최소 티켓, 기본 값은 테이블의 경우 1, 인덱스는 2
③maxtrans: 255
- free space: dml이 자주 발생하면 단편화가 생기는데 오라클 서버가 알아서 병합작업을 진행함.
* OMF(Oracle Managed file)
- 반대는 UMF(User Managed file)
- db_create_file_dest 파라메터만 수정해주면 알아서 파일이름, 사이즈를 정해서 생성한다.
* 테이블 스페이스 관리
- table space를 쪼개 들어가면 extent 라는 공간으로 쪼개지는데 한 extent에 insert가 많이 일어나서 확장이 필요하다면 공간할당을 해야하는데, extent 공간 할당의 방법이 두가지로 나누어진다.
① LMT: Locally management table space. 일반적으로 이걸 쓴다. 표준화까지 됨.
- table space 자신이 공간에 대한 정보를 bitmap을 통해 관리한다.
- bitmap(전광판이라 생각하면 됨)으로 인접한 사용 가능 extent를 미리 파악해둔다.
②DMT: Dictionary management table space: 이전 버젼과 호환성때문에만 지원한다(8i 이전)
- data dictionary에서 extent를 관리한다.
- free extent에 대한 정보가 DIC에 저장되어 있는데(예: dba_extens) tablespace를 위한 extent 요구가 많아지면 경합이 발생한다.
- freelist를 계속 유지하고 있기에 extent들에 대한 정보를 계속 갱신해야 한다=성능
2012년 4월 3일 화요일
admin ws1 둘째날
이전 review
*DB: 데이터들의 집합. 통합/저장/공유 가능한 데이터 집합, 저장 영역이 data file
: control file + data file + redo log file을 합쳐 DB라고 함.
*control file: db이름, creation date, datafile 이름/위치, redo log 이름/위치, structure
: control file이 마운트, 오픈해야 운영 가능
*database block size 8k: 기본값이며 standard block size, primary block size 라고도 부름
-db 생성시 자동으로 생성되는 테이블은 8k 로 만들수밖에 없음: SYSTEM, SYSAUX
-block size를 변경할 수도 있지만 변경하려면 SGA의 db duffer cache도 바꿔야하기에 instance 설정값 즉 parameter 파일도 변경이 필요하다.
*extent: 최소 5개의 블록을 모아 extent라고 한다. extent 안의 블록들은 반드시 연속적이어야 한다. segment가 더 필요할 때 extent 단위로 공간을 할당.
- 시스템마다, table space를 만들때마다 extent 사이즈를 다르게 만들 수 있음.
*객체: data를 저장하기 위한 역할들을 수행하기 위해 저장하고 있는 것들을 객체라고 하고 객체들의 집합이 스키마이며 스키마들의 총 합을 DB라고 한다.
*객체들 중에서 extent가 필요한 객체들을 모은 것이 segment이다. 이들은 데이터 값들이 필요하기에 extent가 필요.
*segment가 저장되는 위치가 Table Space
*예를 들어 u01.dbf 파일이 1G이고 users table space와 연결되어 있고 얘밖에 없으면 users table space의 용량은 1G이다. 논리적으로는 users table space가 되는거고, 물리적으론 u01.dbf 파일이 된다. 만약 user가 emp 테이블을 만든다면 u01.dbf 내에 만들게 된다.
*EM 주소: http://hostname:1158/em
isql주소: http://hostname:5560/isqlplus
리스너 포트번호: 1521
*isqlplus에 로그인시 SYS 사용자로는 로그인 불가. isqlplus dba를 써야하는데 webdba란 롤을 만들어줘야 한다.
11g에선 없어지고 developer로 통합되었다.
*sqlplus hr/hr @script.sql: 로그인후 바로 sql 스크립트 실행
*DB startup 상태
 1. shutdown 상태
1. shutdown 상태
- offlie, closed 상태
- Backup & recovery 진행 가능
- SYSDBA, SYSOPER만 startup 가능
2. Nomount 상태
- Instance만 올린 상태: SGA, Background process, alert + trace log file 활성화됨
- Instance를 올리려면 Parameter 파일이 필요.
① server parameter file: 우선순위가 높음 spfile<sid>.ora 형식이며 직접 수정은 불가하고 ALTER system set 명령으로 수정가능, 재시작 필요 없음, 9i부터 생김
② pfile: init<sid>.ora 형식이며 직접 수정 가능하나 적용하려면 db 재시작 필요.
-pfile로 시작하려면 startup pfile='경로/이름'
- ALTER DATABASE nomount
- SYSDBA, SYSOPER만 접속 가능
- Create DB, Create Control file(Recreation) 진행 가능
3. Mount 상태
- Control file를 올리면서 Instance file과 결합됨: Parameter 파일에 instance name, dbname참조
- Control file의 위치는 Parameter 파일에 적힘.
- Control file에 data file, online redo log file 의 위치와 이름이 적혀있으나 실제 존재하는지는 확인하지 않는다.
- ALTER DATABASE mount
- DBA만 접속 가능
- DB mode 변경(no archive log mode, archive log mode), db 전체 full 복구, DB 구조 변경
4. Open 상태
- 일반유저도 들어올 수 있는 상태
- 이때도 Control file을 읽어들이며 Data file, Online redo log file의 존재여부도 체크한다.
만약 두 파일이 없다면 error가 나타나며 recovery mode로 진입한다 by SMON
- ALTER DATABASE open
* Shutdown 종류
 - Abort: 아주 비정상적인 종료
- Abort: 아주 비정상적인 종료
- shutdown abort나 Instance failure나 startup force 하게 되면 db 일관성이 떨어진다.
-수행중인 sql 문장이 terminate, 접속중인 user 강제끊김, db와 redo log buffer가 disk에 쓰여지지도 않음, commit 안된 tx가 rollback되지도 않음, 파일을 닫지 않고 instance가 종료됨.
- 비정상적인 종료 후에는 instance recovery를 해줘야 하는데 이건 SMON이 자동으로 해준다
* Startup
- Startup force: 강제 재시작
- Startup restrict: 특정 사용자(dba나 sys?)를 제외한 다른 사용자의 접속을 막으며 open
*DB: 데이터들의 집합. 통합/저장/공유 가능한 데이터 집합, 저장 영역이 data file
: control file + data file + redo log file을 합쳐 DB라고 함.
*control file: db이름, creation date, datafile 이름/위치, redo log 이름/위치, structure
: control file이 마운트, 오픈해야 운영 가능
*database block size 8k: 기본값이며 standard block size, primary block size 라고도 부름
-db 생성시 자동으로 생성되는 테이블은 8k 로 만들수밖에 없음: SYSTEM, SYSAUX
-block size를 변경할 수도 있지만 변경하려면 SGA의 db duffer cache도 바꿔야하기에 instance 설정값 즉 parameter 파일도 변경이 필요하다.
*extent: 최소 5개의 블록을 모아 extent라고 한다. extent 안의 블록들은 반드시 연속적이어야 한다. segment가 더 필요할 때 extent 단위로 공간을 할당.
- 시스템마다, table space를 만들때마다 extent 사이즈를 다르게 만들 수 있음.
*객체: data를 저장하기 위한 역할들을 수행하기 위해 저장하고 있는 것들을 객체라고 하고 객체들의 집합이 스키마이며 스키마들의 총 합을 DB라고 한다.
*객체들 중에서 extent가 필요한 객체들을 모은 것이 segment이다. 이들은 데이터 값들이 필요하기에 extent가 필요.
*segment가 저장되는 위치가 Table Space
*예를 들어 u01.dbf 파일이 1G이고 users table space와 연결되어 있고 얘밖에 없으면 users table space의 용량은 1G이다. 논리적으로는 users table space가 되는거고, 물리적으론 u01.dbf 파일이 된다. 만약 user가 emp 테이블을 만든다면 u01.dbf 내에 만들게 된다.
*EM 주소: http://hostname:1158/em
isql주소: http://hostname:5560/isqlplus
리스너 포트번호: 1521
*isqlplus에 로그인시 SYS 사용자로는 로그인 불가. isqlplus dba를 써야하는데 webdba란 롤을 만들어줘야 한다.
11g에선 없어지고 developer로 통합되었다.
*sqlplus hr/hr @script.sql: 로그인후 바로 sql 스크립트 실행
*DB startup 상태

- offlie, closed 상태
- Backup & recovery 진행 가능
- SYSDBA, SYSOPER만 startup 가능
2. Nomount 상태
- Instance만 올린 상태: SGA, Background process, alert + trace log file 활성화됨
- Instance를 올리려면 Parameter 파일이 필요.
① server parameter file: 우선순위가 높음 spfile<sid>.ora 형식이며 직접 수정은 불가하고 ALTER system set 명령으로 수정가능, 재시작 필요 없음, 9i부터 생김
② pfile: init<sid>.ora 형식이며 직접 수정 가능하나 적용하려면 db 재시작 필요.
-pfile로 시작하려면 startup pfile='경로/이름'
- ALTER DATABASE nomount
- SYSDBA, SYSOPER만 접속 가능
- Create DB, Create Control file(Recreation) 진행 가능
3. Mount 상태
- Control file를 올리면서 Instance file과 결합됨: Parameter 파일에 instance name, dbname참조
- Control file의 위치는 Parameter 파일에 적힘.
- Control file에 data file, online redo log file 의 위치와 이름이 적혀있으나 실제 존재하는지는 확인하지 않는다.
- ALTER DATABASE mount
- DBA만 접속 가능
- DB mode 변경(no archive log mode, archive log mode), db 전체 full 복구, DB 구조 변경
4. Open 상태
- 일반유저도 들어올 수 있는 상태
- 이때도 Control file을 읽어들이며 Data file, Online redo log file의 존재여부도 체크한다.
만약 두 파일이 없다면 error가 나타나며 recovery mode로 진입한다 by SMON
- ALTER DATABASE open
* Shutdown 종류

- shutdown abort나 Instance failure나 startup force 하게 되면 db 일관성이 떨어진다.
-수행중인 sql 문장이 terminate, 접속중인 user 강제끊김, db와 redo log buffer가 disk에 쓰여지지도 않음, commit 안된 tx가 rollback되지도 않음, 파일을 닫지 않고 instance가 종료됨.
- 비정상적인 종료 후에는 instance recovery를 해줘야 하는데 이건 SMON이 자동으로 해준다
* Startup
- Startup force: 강제 재시작
- Startup restrict: 특정 사용자(dba나 sys?)를 제외한 다른 사용자의 접속을 막으며 open
시나리오별 내부진행상황
1. isqlplus 를 통함 로그인
- connection이 없다면 user process는 서버측의 listner로 요청을 하게 되고 listner는 이 요청이 유효한지 판단하고 Server process로 전달함.(REDIRECT라고도 함)
- Server Process가 리스너로부터 받은 요청을 User process 측으로 응답해줌
- 로그인을 성공하면 Connection이 생성됨.
2. select * from emp; 을 실행할 경우 내부의 진행상황
일단 connection 해야함
- client측에서 user process를 생성
- userprocess는 server로 해당 문장을 요청함(request)
- server process는 instance를 통해 DB에 접속하려 함.
- 문장에 대해 SGA의 Shared pool의 Library cache에서
① Parsing 단계
soft parse-이전에 사용된 문장이 있다면 검사를 진행하지 않음
hard parse-⑴ syntax check:문장의 구조가 맞는지 확인
⑵ symantics check: 스키마에 있는 오브젝트인지, 권한이 있는지 등 확인. 이때 RC에 이전에 검색했던 data dictionary가 있다면 더 빨리 처리.
⑶ pased code 생성: 파싱이 완료되었다는 코드
⑷ excution plan: optimizer가 실행함
② excute 단계
결과값을 가지러 DB buffer cache를 검색함. 이전에 emp 테이블을 검색한적이 있다면 Server process는 메모리에서 바로 그 결과값을 가져갈 수 있음
결과값이 있으면 cache hit=logical read, 없다면 cache miss=physical read: disk I/O 발생
③ fetch(인출) 단계
fetch 단계는 select절에만 있음.
3. update emp set sal=5000 where sal=1500; 을 실행할 경우 내부의 진행상황
① User process가 명령을 받아 Server Process에게 요청.
② Parsing 단계
③ excute 단계
실행이전엔 DB buffer cache에 1500이 기록되어 있음. 실행되면 DB buffer cache는 5000으로 변경되고 1500은 undo segment로 옮겨짐(before image. rollback과 read consistency를 위해)
※ cache: 순서에 따라 처리하는게 목적인 메모리
※ buffer: 순서에 상관없이 저장하는 목적의 메모리
※ buffer cache: 순서에 맞게 저장된 메모리
4. commit; 을 실행할 경우
서버프로세스에서 commit을 받으면 제일 먼저 반응하는 메모리가 Redo log buffer이다.
LGWR process에 의해 online redolog file에 기록을 남김(이게 완료되면 commited를 볼 수 있다).
그래도 db file의 값은 아직 1500이고 db buffer cache의 dirty buffer가 5000의 값으로 되어있으며
select로 조회를 하면 db buffer cache의 정보를 보여준다.
DBWR process에 의해 dirty buffer들이 data file로 옮겨진후 free buffer로 바뀐다.
- connection이 없다면 user process는 서버측의 listner로 요청을 하게 되고 listner는 이 요청이 유효한지 판단하고 Server process로 전달함.(REDIRECT라고도 함)
- Server Process가 리스너로부터 받은 요청을 User process 측으로 응답해줌
- 로그인을 성공하면 Connection이 생성됨.
2. select * from emp; 을 실행할 경우 내부의 진행상황
일단 connection 해야함
- client측에서 user process를 생성
- userprocess는 server로 해당 문장을 요청함(request)
- server process는 instance를 통해 DB에 접속하려 함.
- 문장에 대해 SGA의 Shared pool의 Library cache에서
① Parsing 단계
soft parse-이전에 사용된 문장이 있다면 검사를 진행하지 않음
hard parse-⑴ syntax check:문장의 구조가 맞는지 확인
⑵ symantics check: 스키마에 있는 오브젝트인지, 권한이 있는지 등 확인. 이때 RC에 이전에 검색했던 data dictionary가 있다면 더 빨리 처리.
⑶ pased code 생성: 파싱이 완료되었다는 코드
⑷ excution plan: optimizer가 실행함
② excute 단계
결과값을 가지러 DB buffer cache를 검색함. 이전에 emp 테이블을 검색한적이 있다면 Server process는 메모리에서 바로 그 결과값을 가져갈 수 있음
결과값이 있으면 cache hit=logical read, 없다면 cache miss=physical read: disk I/O 발생
③ fetch(인출) 단계
fetch 단계는 select절에만 있음.
3. update emp set sal=5000 where sal=1500; 을 실행할 경우 내부의 진행상황
① User process가 명령을 받아 Server Process에게 요청.
② Parsing 단계
③ excute 단계
실행이전엔 DB buffer cache에 1500이 기록되어 있음. 실행되면 DB buffer cache는 5000으로 변경되고 1500은 undo segment로 옮겨짐(before image. rollback과 read consistency를 위해)
※ cache: 순서에 따라 처리하는게 목적인 메모리
※ buffer: 순서에 상관없이 저장하는 목적의 메모리
※ buffer cache: 순서에 맞게 저장된 메모리
4. commit; 을 실행할 경우
서버프로세스에서 commit을 받으면 제일 먼저 반응하는 메모리가 Redo log buffer이다.
LGWR process에 의해 online redolog file에 기록을 남김(이게 완료되면 commited를 볼 수 있다).
그래도 db file의 값은 아직 1500이고 db buffer cache의 dirty buffer가 5000의 값으로 되어있으며
select로 조회를 하면 db buffer cache의 정보를 보여준다.
DBWR process에 의해 dirty buffer들이 data file로 옮겨진후 free buffer로 바뀐다.
admin ws1 첫날
sqlplus는 별도의 user process가 없이 client와 process가 일치형.
그외 isqlplus 등은 listner가 필요하다.
* 오라클 서버
-Instance + DB 를 Oracle Server라 부른다.
-Instance는 SGA + Background process
-구조적으로 보면 Memory + Process + Storage
-각 실행중인 오라클 database는 user들이 instance를 통해 db에 접속하기에 반드 시 instance와 연결되어 있어야 한다.
-Oracle instance 시작 후 Software(엔진)은 instance와 특정 database를 연결해야하는데 이 연결을 mount 되었다 라고 한다.
 * 메모리
* 메모리
-SGA와 PGA로 나뉘어짐
-PGA: 각 서버 프로세스에 존재하는 개별 전용 메모리, 사용자가 요청한 작업을 개별적으로 실행하기 위해 서버 프로세스에게 개별 할당하는 메모리. 각 서버프로세스에 정보들을 저장하고 클라이언트의 request를 처리하는 메모리.
-SGA: SHARED 란 단어가 제일 중요.
-필수메모리: shared pool, db buffer cache, redo buffer
-옵션메모리: large pool(공유풀의 보조 메모리), java pool
-shared pool(구분 없이 아무나 사용가능한 메모리웅덩이): library cache + data dictionary(RC:row cache-data dictionary가 전부 행으로 저장되어 있기에), user들이 공통으로 사용하는 공간.
-library cache: shared sql room + shared pl/sql room
-redo log buffer: 모든 변경 데이터를 기록함(언제/어떤 data가 어떤 값으로)
 * 프로세스
* 프로세스
-User, Server, Background Process
-SGA와 DB 사이에 있는 프로세스는 DBWn, LGWR 뿐임.
-LGWR: redolog를 기록하는 프로세스. 1번 파일과 2번 파일이 있을때 1번파일을 다 사용하여 2번파일을 사용할때 전환되는 것을 log switch라고 하고 로그스위치가 발생하면 checkpoint도 발생한다. 2번 파일도 다 차서 1번파일이 3번파일로 되면 1번파일을 참조해 복구할 수 없게 되는데 이걸 막기 위해 Archive를 사용해 1번 파일을 archive log file로 복사하기도 한다. 이때 사용되는 프로세스가 ARCn or ARCH 프로세스.
-SMON: instance를 관리.database 시스템이 잘못되면 instance recovery를 주로 담당
-PMON: 프로세스 관리.프로세스 정리나 복구
-CKPT: data file header와 control 파일에 동시에 최근 변경된 checkpoint 기록, 동기화를 위해 scn 남김
※SCN: commit될때마다 증가되는 번호
 -DBWn or DBWR: 만약 SGA의 database buffer cache에서 data file로 기록이 필요할 경우 이벤트가 발생할 때마다 기록한다면 매번 disk I/O가 발생하기에 이걸 줄이고자 data file에 기록이 필요한 buffer cache들을 따로 dirty buffer라고 체크하여 모은 후(dirty list) 한번에 data file에 기록한다. data buffer cache의 상태에 따른 종류: pinned(사용중), free(미사용), clean(곧 age out될 대상)
-DBWn or DBWR: 만약 SGA의 database buffer cache에서 data file로 기록이 필요할 경우 이벤트가 발생할 때마다 기록한다면 매번 disk I/O가 발생하기에 이걸 줄이고자 data file에 기록이 필요한 buffer cache들을 따로 dirty buffer라고 체크하여 모은 후(dirty list) 한번에 data file에 기록한다. data buffer cache의 상태에 따른 종류: pinned(사용중), free(미사용), clean(곧 age out될 대상)
* 스토리지
-필수파일: Control file(가장 중요한 파일, 구조정보 등 저장), data file, Onlie redo log file
-parameter file: Instance를 startup하기 위한 파일
-password file: 원격으로 db에 접속하는 user들의 암호들 저장.
-backup file: 말그래도 data base의 백업파일
-archive log file: redo log 파일들을 보조하는 파일
-Trace file: database에서 일어나는 내부 에러들이 프로세스에 의해 감지되고 덤프됨
-Alert log file: database에서 발생한 모든 이벤트를 기록. 이 내용중 구체적인 내용이 기록되는 것이 트레이스 파일
-Tablespace: database의 가장 큰 논리적 영역으로 하나의 tbs는 여러개의 datafile로 이루어질 수 있으며 datafile은 하나의 tbs와 연결 가능.
big file tablespace와 small file tablespace가 있으며 주로 쓰는건 small file tablespace.
-database 생성시 SYSTEM(data dictionary등), SYSAUX(10g부터) 테이블스페이스가 생성됨. 이들은 db가 정상으로 돌아가려면 꼭 online 상태여야 함.
 -tablespace>segment>extent>data block
-tablespace>segment>extent>data block
-table과 index 같은 객체가 다른 객체와 다른 점: data를 저장할 수 있는 공간을 가지는 객체임, 이걸 세그먼트라 부름.
-segment는 하나 이상의 extent로 구성 가능
-extent 의 block들은 반드시 연속적이어야 함. extent 자체가 data block들이 연속적으로 모인 것.
-data block size의 기본값은 8k, DW같은 환경에선 큰 편이 좋고 OLTP 같은 환경에선 작은 편이 좋다. 단, ORACLE에서 제공하는 특징중 하나로 한 DB내에서 다른 db block size를 설정 할 수 있다.

-OS block: 파일을 제일 작게 쪼개면 os block
-Extent 와 Data file은 1:1 관계, Tablespace와 Data file은 1:다 관계
-segment: 특정 논리적 객체에 할당된 extent를 모은 것. 즉, 데이터의 종류에 따른 구분. 테이블에 db를 저장하면 테이블 세그먼트, 인덱스라면 인덱스 세그먼트, 언두라면 언두 세그먼트 등. segment는 동적으로 오라클DB에 의해 할당됨.
그외 isqlplus 등은 listner가 필요하다.
* 오라클 서버
-Instance + DB 를 Oracle Server라 부른다.
-Instance는 SGA + Background process
-구조적으로 보면 Memory + Process + Storage
-각 실행중인 오라클 database는 user들이 instance를 통해 db에 접속하기에 반드 시 instance와 연결되어 있어야 한다.
-Oracle instance 시작 후 Software(엔진)은 instance와 특정 database를 연결해야하는데 이 연결을 mount 되었다 라고 한다.

-SGA와 PGA로 나뉘어짐
-PGA: 각 서버 프로세스에 존재하는 개별 전용 메모리, 사용자가 요청한 작업을 개별적으로 실행하기 위해 서버 프로세스에게 개별 할당하는 메모리. 각 서버프로세스에 정보들을 저장하고 클라이언트의 request를 처리하는 메모리.
-SGA: SHARED 란 단어가 제일 중요.
-필수메모리: shared pool, db buffer cache, redo buffer
-옵션메모리: large pool(공유풀의 보조 메모리), java pool
-shared pool(구분 없이 아무나 사용가능한 메모리웅덩이): library cache + data dictionary(RC:row cache-data dictionary가 전부 행으로 저장되어 있기에), user들이 공통으로 사용하는 공간.
-library cache: shared sql room + shared pl/sql room
-redo log buffer: 모든 변경 데이터를 기록함(언제/어떤 data가 어떤 값으로)

-User, Server, Background Process
-SGA와 DB 사이에 있는 프로세스는 DBWn, LGWR 뿐임.
-LGWR: redolog를 기록하는 프로세스. 1번 파일과 2번 파일이 있을때 1번파일을 다 사용하여 2번파일을 사용할때 전환되는 것을 log switch라고 하고 로그스위치가 발생하면 checkpoint도 발생한다. 2번 파일도 다 차서 1번파일이 3번파일로 되면 1번파일을 참조해 복구할 수 없게 되는데 이걸 막기 위해 Archive를 사용해 1번 파일을 archive log file로 복사하기도 한다. 이때 사용되는 프로세스가 ARCn or ARCH 프로세스.
-SMON: instance를 관리.database 시스템이 잘못되면 instance recovery를 주로 담당
-PMON: 프로세스 관리.프로세스 정리나 복구
-CKPT: data file header와 control 파일에 동시에 최근 변경된 checkpoint 기록, 동기화를 위해 scn 남김
※SCN: commit될때마다 증가되는 번호

* 스토리지
-필수파일: Control file(가장 중요한 파일, 구조정보 등 저장), data file, Onlie redo log file
-parameter file: Instance를 startup하기 위한 파일
-password file: 원격으로 db에 접속하는 user들의 암호들 저장.
-backup file: 말그래도 data base의 백업파일
-archive log file: redo log 파일들을 보조하는 파일
-Trace file: database에서 일어나는 내부 에러들이 프로세스에 의해 감지되고 덤프됨
-Alert log file: database에서 발생한 모든 이벤트를 기록. 이 내용중 구체적인 내용이 기록되는 것이 트레이스 파일
-Tablespace: database의 가장 큰 논리적 영역으로 하나의 tbs는 여러개의 datafile로 이루어질 수 있으며 datafile은 하나의 tbs와 연결 가능.
big file tablespace와 small file tablespace가 있으며 주로 쓰는건 small file tablespace.
-database 생성시 SYSTEM(data dictionary등), SYSAUX(10g부터) 테이블스페이스가 생성됨. 이들은 db가 정상으로 돌아가려면 꼭 online 상태여야 함.

-table과 index 같은 객체가 다른 객체와 다른 점: data를 저장할 수 있는 공간을 가지는 객체임, 이걸 세그먼트라 부름.
-segment는 하나 이상의 extent로 구성 가능
-extent 의 block들은 반드시 연속적이어야 함. extent 자체가 data block들이 연속적으로 모인 것.
-data block size의 기본값은 8k, DW같은 환경에선 큰 편이 좋고 OLTP 같은 환경에선 작은 편이 좋다. 단, ORACLE에서 제공하는 특징중 하나로 한 DB내에서 다른 db block size를 설정 할 수 있다.

-Extent 와 Data file은 1:1 관계, Tablespace와 Data file은 1:다 관계
-segment: 특정 논리적 객체에 할당된 extent를 모은 것. 즉, 데이터의 종류에 따른 구분. 테이블에 db를 저장하면 테이블 세그먼트, 인덱스라면 인덱스 세그먼트, 언두라면 언두 세그먼트 등. segment는 동적으로 오라클DB에 의해 할당됨.
2012년 3월 28일 수요일
Single functions
문자 함수
LOWER: 전부 소문자로
UPPPER: 전부 대문자로
INITCAP: 맨 앞만 대문자로
CONCAT('Hello', 'World')=> HelloWorld
SUBSTR('HelloWorld',1,5)=> Hello
LENGTH('HelloWorld')=> 10 INSTR('HelloWorld', 'W')=> 6
LPAD(salary,10,'*')=> *****24000 =LPAD(' ',10,'*') 식으로도 가능 RPAD(salary, 10, '*')=> 24000*****
REPLACE('JACK and JUE','J','BL')=> BLACK and BLUE
TRIM('H' FROM 'HelloWorld')=> elloWorld =첫글자나 맨 뒤글자만 됨
숫자 함수
ROUND
TRUNC
MOD: 나머지값
날짜 함수
SYSDATE
※date+number = number를 일수로 계산함, 결과는 date
date-number = 위와 마찬가지, 결과는 date
date-date = 둘의 차이를 일수로 계산하여 보여줌, 결과는 일수
date+number/24 = 일수/24이므로 시간임. 시간을 + 계산하여 결과로 date를 보여줌
MONTHS_BETWEEN('date1', 'date2'): 두 날짜사이의 달수를 계산함
ADD_MONTHS('date1', number): date1에서 number만큼의 달수를 더함
NEXT_DAY('date', 'monday'):date의 다음 월요일을 나타냄
LAST_DAY('date'):해당 달의 마지막날을 나타냄
ROUND(SYSDATE,'MONTH'):16일 이후는 반올림하여 다음달로 표시함.
ROUND(SYSDATE,'YEAR'):7월 1일 이후는 반올림하여 다음 해로 표시함.
TRUNC(SYSDATE,'MONTH'):그 달의 1일로 표시함.
TRUNC(SYSDATE,'YEAR'):해당 년도의 1월 1일로 표시함.
변환 함수
TO_CHAR(date,'[fm]format_model')
TO_CHAR(number, 'format_model')
TO_NUMBER(char[, 'format_model'])
TO_DATE(char[, '[fx]format_model'])
NULL 함수
NVL(expr1, expr2): expr1에 있는 NULL 값을 전부 expr2를 리턴, date, number, char, varchar2 다 가능, 주의! expr1과 expr2는 데이터타입이 같아야함. 틀리면 to_char, to_num으로 바꿔서 해야댐.
NVL2(expr1, expr2, expr3): expr1에 있는 값이 널이 아니면 expr2를, 널이면 expr3를 리턴
NULLIF(expr1, expr2): expr1과 expr2가 같으면 null을 리턴하고, 같지 않으면 expr1을 리턴
COALESCE(expr1, expr2, ...exprn): expr1이 null이 아니면 expr1을 리턴, null이면 expr2를 리턴, expr1과 expr2가 null이면 expr3을 리턴)
IF-THEN-ELSE 식 함수
CASE expr WHEN comparison_expr1 THEN return1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
예시)
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END AS "REVISED_SALARY"
FROM employees;
DECODE(col|expression, search1, result1
[, search2, result2,...,]
[, default])
예시)
SELECT last_name, job_id, salary,
DECODE(job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary)
AS REVISED_SALARY
FROM employees;
LOWER: 전부 소문자로
UPPPER: 전부 대문자로
INITCAP: 맨 앞만 대문자로
CONCAT('Hello', 'World')=> HelloWorld
SUBSTR('HelloWorld',1,5)=> Hello
LENGTH('HelloWorld')=> 10 INSTR('HelloWorld', 'W')=> 6
LPAD(salary,10,'*')=> *****24000 =LPAD(' ',10,'*') 식으로도 가능 RPAD(salary, 10, '*')=> 24000*****
REPLACE('JACK and JUE','J','BL')=> BLACK and BLUE
TRIM('H' FROM 'HelloWorld')=> elloWorld =첫글자나 맨 뒤글자만 됨
숫자 함수
ROUND
TRUNC
MOD: 나머지값
날짜 함수
SYSDATE
※date+number = number를 일수로 계산함, 결과는 date
date-number = 위와 마찬가지, 결과는 date
date-date = 둘의 차이를 일수로 계산하여 보여줌, 결과는 일수
date+number/24 = 일수/24이므로 시간임. 시간을 + 계산하여 결과로 date를 보여줌
MONTHS_BETWEEN('date1', 'date2'): 두 날짜사이의 달수를 계산함
ADD_MONTHS('date1', number): date1에서 number만큼의 달수를 더함
NEXT_DAY('date', 'monday'):date의 다음 월요일을 나타냄
LAST_DAY('date'):해당 달의 마지막날을 나타냄
ROUND(SYSDATE,'MONTH'):16일 이후는 반올림하여 다음달로 표시함.
ROUND(SYSDATE,'YEAR'):7월 1일 이후는 반올림하여 다음 해로 표시함.
TRUNC(SYSDATE,'MONTH'):그 달의 1일로 표시함.
TRUNC(SYSDATE,'YEAR'):해당 년도의 1월 1일로 표시함.
변환 함수
TO_CHAR(date,'[fm]format_model')
TO_CHAR(number, 'format_model')
TO_NUMBER(char[, 'format_model'])
TO_DATE(char[, '[fx]format_model'])
NULL 함수
NVL(expr1, expr2): expr1에 있는 NULL 값을 전부 expr2를 리턴, date, number, char, varchar2 다 가능, 주의! expr1과 expr2는 데이터타입이 같아야함. 틀리면 to_char, to_num으로 바꿔서 해야댐.
NVL2(expr1, expr2, expr3): expr1에 있는 값이 널이 아니면 expr2를, 널이면 expr3를 리턴
NULLIF(expr1, expr2): expr1과 expr2가 같으면 null을 리턴하고, 같지 않으면 expr1을 리턴
COALESCE(expr1, expr2, ...exprn): expr1이 null이 아니면 expr1을 리턴, null이면 expr2를 리턴, expr1과 expr2가 null이면 expr3을 리턴)
IF-THEN-ELSE 식 함수
CASE expr WHEN comparison_expr1 THEN return1
[WHEN comparison_expr2 THEN return_expr2
WHEN comparison_exprn THEN return_exprn
ELSE else_expr]
END
예시)
SELECT last_name, job_id, salary,
CASE job_id WHEN 'IT_PROG' THEN 1.10*salary
WHEN 'ST_CLERK' THEN 1.15*salary
WHEN 'SA_REP' THEN 1.20*salary
ELSE salary END AS "REVISED_SALARY"
FROM employees;
DECODE(col|expression, search1, result1
[, search2, result2,...,]
[, default])
예시)
SELECT last_name, job_id, salary,
DECODE(job_id, 'IT_PROG', 1.10*salary,
'ST_CLERK', 1.15*salary,
'SA_REP', 1.20*salary,
salary)
AS REVISED_SALARY
FROM employees;

ALTER 사용법(작성중)
1. 컬럼 추가
형식
ALTER TABLE table
ADD (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
ADD (job_id VARCHAR2(9);
2. 컬럼 변경
형식
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
MODIFY (job_id VARCHAR2(20));
3. 컬럼 제거
형식
ALTER TABLE table
DROP COLUMN column;
예시
ALTER TABLE dep80
DROP COLUMN job_id;
형식
ALTER TABLE table
ADD (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
ADD (job_id VARCHAR2(9);
2. 컬럼 변경
형식
ALTER TABLE table
MODIFY (column datatype [DEFAULT expr] [, column datatype]...);
예시
ALTER TABLE dep80
MODIFY (job_id VARCHAR2(20));
3. 컬럼 제거
형식
ALTER TABLE table
DROP COLUMN column;
예시
ALTER TABLE dep80
DROP COLUMN job_id;
2012년 3월 27일 화요일
TABLE 생성 및 관리(작성중)
테이블/열 이름 규칙
-문자로 시작
-1~30자까지 가능
-특수문자는 _, $, #만 가능
* CREATE TABLE
1. CREATE 형식: CREATE TABLE table (column datatype)
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr])
다른 유저의 테이블을 보고 싶을때 schema를 사용
schema란=특정 유저가 소유하고 있는 모든 객체들의 집합을 스키마라 하고 이름을 유저이름으로 함
남의 테이블을 참조할때는 반드시 스키마를 명시해야함
예) user hr이 scott의 emp테이블을 보고 싶을때
select * from scott.emp
다른 유저의 것을 볼때는 스키마 생략 불가
DEFAULT 옵션은 값을 입력하지 않을때 자동으로 들어가는 값
다른 컬럼의 이름, nextval, currval은 못쓴다.
예)
CREATE TABLE hire_dates
(id NUMBER(8),
hire_date DATE DEFAULT SYSDATE);
2. CREATE
CREATE TABLE emp
( emp_id number(6) constraint emp_empid_pk primary key,
f_name varchar2(20),
l_name varchar2(25) constraint emp_lname_nn not null,
email varchar2(25) constraint emp_email_nn not null
constraint emp_email_uk unique,
phone_number varchar2(20),
hire_date date constraint emp_hiredate_nn not null,
job_id varchar2(10) constraint emp_jobid_nn not null,
salary number(8,2) constraint emp_salary_ck check (salary>0),
commission_pct number(2,2),
manager_id number(6),
department_id number(4) constraint emp_depid_fk references departments (department_id));
-문자로 시작
-1~30자까지 가능
-특수문자는 _, $, #만 가능
* CREATE TABLE
1. CREATE 형식: CREATE TABLE table (column datatype)
CREATE TABLE [schema.]table
(column datatype [DEFAULT expr])
다른 유저의 테이블을 보고 싶을때 schema를 사용
schema란=특정 유저가 소유하고 있는 모든 객체들의 집합을 스키마라 하고 이름을 유저이름으로 함
남의 테이블을 참조할때는 반드시 스키마를 명시해야함
예) user hr이 scott의 emp테이블을 보고 싶을때
select * from scott.emp
다른 유저의 것을 볼때는 스키마 생략 불가
DEFAULT 옵션은 값을 입력하지 않을때 자동으로 들어가는 값
다른 컬럼의 이름, nextval, currval은 못쓴다.
예)
CREATE TABLE hire_dates
(id NUMBER(8),
hire_date DATE DEFAULT SYSDATE);
2. CREATE
CREATE TABLE emp
( emp_id number(6) constraint emp_empid_pk primary key,
f_name varchar2(20),
l_name varchar2(25) constraint emp_lname_nn not null,
email varchar2(25) constraint emp_email_nn not null
constraint emp_email_uk unique,
phone_number varchar2(20),
hire_date date constraint emp_hiredate_nn not null,
job_id varchar2(10) constraint emp_jobid_nn not null,
salary number(8,2) constraint emp_salary_ck check (salary>0),
commission_pct number(2,2),
manager_id number(6),
department_id number(4) constraint emp_depid_fk references departments (department_id));
2012년 3월 26일 월요일
TCL
Transaction Control Language
DML은 마지막에 TCL이 필요함
트랜잭션 길이가 짧고 갯수가 많은 상황: 은행=OLTP
트랜잭선 길이가 길고 갯수가 적은 상황: dw or batch
※ iSQLPLUS에서 autocommit on을 하면 절대 안된다.
아래 한장으로 대략 거의 모든 설명이 된다.
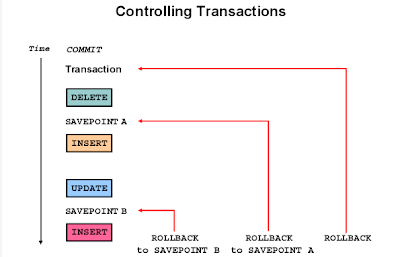
1. 명령어들
COMMIT
SAVE POINT name
ROLLBACK
ROLLBACK TO SAVEPOINT name
2. COMMIT, ROLLBACK이 자동으로 되는 상황
exit를 하면 명시적으로 commit이 발생됨(iSQLPLUS가 정상적으로 종료되어도)
장애 발생하면 자동 rollback 처리됨(iSQLPLUS 창을 닫으면 비정상 종료로 처리함)
DDL = auto commit
DCL = auto commit
3. PENDING STATE: DML을 치고 TCL을 아직 안친 상태
데이터를 이전으로 ROLLBACK 가능
SELECT로 DML 결과를 검토 가능
다른 사용자는 DML 전의 상태만 볼수 있음
DML 작업중인 행은 LOCK 상태이기에 다른 사용자는 변경 불가
4. Read Consistency
-데이터는 항상 commit된 데이터만 보여줘야 한다.
-데이터를 읽는 중(select)에는 다른 사용자가 쓸(insert,update,delete) 수 없다.
-데이터를 쓰는 중에는 다른 사용자가 쓰는 내용을 읽을 수 없다.
5. Read Consistency 구현
-쓰기: select, insert, delete 할 경우 이전 데이터의 복사본을 undo segment에 넣어두고 다른 사용자가 select를 실행시 undo segment 내용을 보여줌.
-커밋되면: undo segment가 지워짐.
-롤백되면: undo segment 내용을 data block으로 다시 이전됨.
DML은 마지막에 TCL이 필요함
트랜잭션 길이가 짧고 갯수가 많은 상황: 은행=OLTP
트랜잭선 길이가 길고 갯수가 적은 상황: dw or batch
※ iSQLPLUS에서 autocommit on을 하면 절대 안된다.
아래 한장으로 대략 거의 모든 설명이 된다.

1. 명령어들
COMMIT
SAVE POINT name
ROLLBACK
ROLLBACK TO SAVEPOINT name
2. COMMIT, ROLLBACK이 자동으로 되는 상황
exit를 하면 명시적으로 commit이 발생됨(iSQLPLUS가 정상적으로 종료되어도)
장애 발생하면 자동 rollback 처리됨(iSQLPLUS 창을 닫으면 비정상 종료로 처리함)
DDL = auto commit
DCL = auto commit
3. PENDING STATE: DML을 치고 TCL을 아직 안친 상태
데이터를 이전으로 ROLLBACK 가능
SELECT로 DML 결과를 검토 가능
다른 사용자는 DML 전의 상태만 볼수 있음
DML 작업중인 행은 LOCK 상태이기에 다른 사용자는 변경 불가
4. Read Consistency
-데이터는 항상 commit된 데이터만 보여줘야 한다.
-데이터를 읽는 중(select)에는 다른 사용자가 쓸(insert,update,delete) 수 없다.
-데이터를 쓰는 중에는 다른 사용자가 쓰는 내용을 읽을 수 없다.
5. Read Consistency 구현
-쓰기: select, insert, delete 할 경우 이전 데이터의 복사본을 undo segment에 넣어두고 다른 사용자가 select를 실행시 undo segment 내용을 보여줌.
-커밋되면: undo segment가 지워짐.
-롤백되면: undo segment 내용을 data block으로 다시 이전됨.
DML 정리(TCL제외)
DML-insert, update, delete
-sql의 CORE
TCL-commit, rollback
* INSERT
1. INSERT 형식: INSERT INTO VALUE
- INSERT INTO table (column1, column2, ...)
VALUES (value1, value2 ...);
- INSERT INTO table
VALUES (value1, value2 ...);
=value 값을 순서에 맞게 다 적어야함
예제)
insert into dep(dep_id, dep_name, man_id, loc_id)
values(75, 'dba',100, 1700);
- Null값을 넣는 방법
1) Implicit method: dep_id, dep_name, man_id, loc_id 가 있으나 생략됐기에 null이 들어감
INSERT INTO dep (dep_id, dep_name)
VALUES (30, 'Purchasing')
2) Explicit method: 직접 null을 명시해서 null값이 들어가게 함
INSERT INTO dep
VALUES (30, 'Purchasing', NULL, NULL);
2. INSERT를 이용한 테이블 복사
- 특정 부분만
INSERT INTO sales_reps(id, name, sal, commission_pct)
SELECT emp_id, l_name, sal, commission_pct
FROM emp
WHERE job_id LIKE '%REP%';
- 전부 복사: 백업이나 마이그레이션을 하는 방법의 주가 될 수 있음
다른 테이블의 내용을 복사해서 내 테이블에 넣는 방법 or 그 반대=데이터를 복사하는 방법
서브쿼리를 사용. 'CTAS'라고도 함
CREATE TABLE copy_emp
AS SELECT *
FROM employees = 여기까지 하면 구조와 data 전부를 복사함
WHERE 1=2 = 이 조건을 주면 맞는 데이터가 전혀 없기 때문에 구조만 복사됨
- Insert에 테이블 대신 서브쿼리 이용 예제
INSERT INTO
(SELECT employee_id, last_name,
email, hire_date, job_id, salary,
department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
* UPDATE
1. UPDATE 형식: UPDATE SET WHERE
- UPDATE table
SET column = value
WHERE condition;
WHERE 절을 안쓰면 전부를 바꿀수 있음 조심
- 여러 값을 서브쿼리를 이용해 바꾸고자 할때.
update emp
set job_id=(select job_id from emp where emp_id=205),
sal=(select sal from emp where emp_id=205)
where emp_id=114;
* DELETE
1. DELETE 형식: DELETE WHERE
- DELETE table
WHERE condition;
예제1) 1개만 지워진다
DELETE FROM departments
WHERE department_name = 'Finance';
예제2) 모두 지워진다- 조심
DELETE FROM copy_emp;
- 다른 테이블을 이용한 열 삭제 예제
DELETE FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE department_name
LIKE '%Public%');
그러나 아마 연관된 레코드가 있다며 무결성 제약 오류가 날 가능성이 크다.(외래키)
-sql의 CORE
TCL-commit, rollback
* INSERT
1. INSERT 형식: INSERT INTO VALUE
- INSERT INTO table (column1, column2, ...)
VALUES (value1, value2 ...);
- INSERT INTO table
VALUES (value1, value2 ...);
=value 값을 순서에 맞게 다 적어야함
예제)
insert into dep(dep_id, dep_name, man_id, loc_id)
values(75, 'dba',100, 1700);
- Null값을 넣는 방법
1) Implicit method: dep_id, dep_name, man_id, loc_id 가 있으나 생략됐기에 null이 들어감
INSERT INTO dep (dep_id, dep_name)
VALUES (30, 'Purchasing')
2) Explicit method: 직접 null을 명시해서 null값이 들어가게 함
INSERT INTO dep
VALUES (30, 'Purchasing', NULL, NULL);
2. INSERT를 이용한 테이블 복사
- 특정 부분만
INSERT INTO sales_reps(id, name, sal, commission_pct)
SELECT emp_id, l_name, sal, commission_pct
FROM emp
WHERE job_id LIKE '%REP%';
- 전부 복사: 백업이나 마이그레이션을 하는 방법의 주가 될 수 있음
다른 테이블의 내용을 복사해서 내 테이블에 넣는 방법 or 그 반대=데이터를 복사하는 방법
서브쿼리를 사용. 'CTAS'라고도 함
CREATE TABLE copy_emp
AS SELECT *
FROM employees = 여기까지 하면 구조와 data 전부를 복사함
WHERE 1=2 = 이 조건을 주면 맞는 데이터가 전혀 없기 때문에 구조만 복사됨
- Insert에 테이블 대신 서브쿼리 이용 예제
INSERT INTO
(SELECT employee_id, last_name,
email, hire_date, job_id, salary,
department_id
FROM employees
WHERE department_id = 50)
VALUES (99999, 'Taylor', 'DTAYLOR',
TO_DATE('07-JUN-99', 'DD-MON-RR'),
'ST_CLERK', 5000, 50);
* UPDATE
1. UPDATE 형식: UPDATE SET WHERE
- UPDATE table
SET column = value
WHERE condition;
WHERE 절을 안쓰면 전부를 바꿀수 있음 조심
- 여러 값을 서브쿼리를 이용해 바꾸고자 할때.
update emp
set job_id=(select job_id from emp where emp_id=205),
sal=(select sal from emp where emp_id=205)
where emp_id=114;
* DELETE
1. DELETE 형식: DELETE WHERE
- DELETE table
WHERE condition;
예제1) 1개만 지워진다
DELETE FROM departments
WHERE department_name = 'Finance';
예제2) 모두 지워진다- 조심
DELETE FROM copy_emp;
- 다른 테이블을 이용한 열 삭제 예제
DELETE FROM employees
WHERE department_id =
(SELECT department_id
FROM departments
WHERE department_name
LIKE '%Public%');
그러나 아마 연관된 레코드가 있다며 무결성 제약 오류가 날 가능성이 크다.(외래키)
2012년 3월 25일 일요일
join 문제풀이
6번문제 5-33p
select e.dep_id department, e.last_name employee, m.last_name colleague
from emp e join emp m
on (e.dep_id=m.dep_id)
and (e.last_name<>m.last_name)
order by e.dep_id, e.last_name, m.last_name
and(e.last_name<>m.last_name)이 중요
문제에 힌트가 너무 없고 결과를 보고 추리를 해야하기 때문에 찾아봤음.. 내 사고가 딸리나
7번문제 5-34p
select e.last_name, e.job_id, d.dep_name, e.sal, j.gra
from emp e join dep d
on (e.dep_id=d.dep_id)
join job_grades j
on e.sal between j.low_sal and j.high_sal
select e.dep_id department, e.last_name employee, m.last_name colleague
from emp e join emp m
on (e.dep_id=m.dep_id)
and (e.last_name<>m.last_name)
order by e.dep_id, e.last_name, m.last_name
and(e.last_name<>m.last_name)이 중요
문제에 힌트가 너무 없고 결과를 보고 추리를 해야하기 때문에 찾아봤음.. 내 사고가 딸리나
7번문제 5-34p
select e.last_name, e.job_id, d.dep_name, e.sal, j.gra
from emp e join dep d
on (e.dep_id=d.dep_id)
join job_grades j
on e.sal between j.low_sal and j.high_sal
2012년 3월 23일 금요일
salary 1000당 * 표시 나오게 하기
10g sql fundamental1_sg1 3-67p의 문제..
이건 교재에도 나오지 않은 내용은데 어떻게 풀라는건지
원하는건 last_name의 8자와 salary 1000당 *하나를 입력하는 것이다.
select substr(last_name,1,8)||' '||lpad(' ', trunc(salary/1000+1),'*')
from employees
order by salary desc;
핵심은 lpad후 ' '을 써서 아무것도 내용을 쓰지 않는 것
좀더 매끄럽게 할 수도 있을거 같은데 나중에 다듬어바야지
이건 교재에도 나오지 않은 내용은데 어떻게 풀라는건지
원하는건 last_name의 8자와 salary 1000당 *하나를 입력하는 것이다.
select substr(last_name,1,8)||' '||lpad(' ', trunc(salary/1000+1),'*')
from employees
order by salary desc;
핵심은 lpad후 ' '을 써서 아무것도 내용을 쓰지 않는 것
좀더 매끄럽게 할 수도 있을거 같은데 나중에 다듬어바야지
nvl2를 이용한 commission 조회
원하는건 commission_pct가 null 값이라면 No commission이란 문자를 리턴하고
null값이 아니라면 그대로 commission_pct를 리턴해주려고 한다.
그래서 간단히 아래와 같이 생각했으나
select last_name,
NVL2(commission_pct, commission_pct, 'No Commission')
from employees;
NVL2(commission_pct, commission_pct, 'No Commission')
*
ERROR at line 2:
ORA-01722: invalid number
에러가 뜬다
좀 찾아보니 nvl2건 coalecse건 리턴하는 값은 둘다 같은 타입이어야 하는 결론이 나왔다.
그래서 아래처럼 바꾸어서 해결.
select last_name,
NVL2(commission_pct, to_char(commission_pct), 'No Commission')
from employees;
null값이 아니라면 그대로 commission_pct를 리턴해주려고 한다.
그래서 간단히 아래와 같이 생각했으나
select last_name,
NVL2(commission_pct, commission_pct, 'No Commission')
from employees;
NVL2(commission_pct, commission_pct, 'No Commission')
*
ERROR at line 2:
ORA-01722: invalid number
에러가 뜬다
좀 찾아보니 nvl2건 coalecse건 리턴하는 값은 둘다 같은 타입이어야 하는 결론이 나왔다.
그래서 아래처럼 바꾸어서 해결.
select last_name,
NVL2(commission_pct, to_char(commission_pct), 'No Commission')
from employees;
요일별 정렬 monday 맨앞으로 오게하기
요일별로 정렬할때 monday가 맨앞으로 오게하기
select last_name, hire_date, to_char(hire_date,'DAY') DAY
from employees
order by to_char(hire_date-1,'D');
D=날짜를 숫자로 표현
1=sunday, 2=monday
이므로 -1을 줘서 monday를 1로 만듬
select last_name, hire_date, to_char(hire_date,'DAY') DAY
from employees
order by to_char(hire_date-1,'D');
D=날짜를 숫자로 표현
1=sunday, 2=monday
이므로 -1을 줘서 monday를 1로 만듬
2012년 3월 20일 화요일
OLTP,OLAP,DW 정의
OLTP: OnLine Transaction Processing
Batch 와 반대되는 개념으로 실시간으로 db의 데이터를 트랜잭션 단위로 갱신/조회하는 처리방식. 은행, 증권사 등에서 씀. 기존과 달리 다수의 client가 거의 동시에 이용할수 있도록 송수신자료를 트랜잭션단위로 압축한것이 특징.
DW: Data Warehouse
수년간 발생한 데이터를 모아서 주제별로 합쳐 분석할 수 있게 하는 통합시스템.
예) 운영데이터, 분산데이터, 시장데이터를 추출하여 DW를 구축하고 그걸 DSS나 OLAP로 분석
※Data Mart: DW의 하위단위라고 볼 수 있으며, DW는 중앙집중식 데이터 집합체의 개념을 가지나, data mart는 데이터 저장소의 역할을 하고 특정 목적을 위해 쉬운 접근성과 사용성을 가진다. DW는 기존 데이터를 어떻게 수집/분석하고 어떻게 재사용할 것인가에 초점을 맞춤
OLAP:OnLine Analytical Processing
위의 DW에서 데이터를 분석해서 의미있는 형태로 만들기 위한 과정및 도구. 의사결정 지원 시스템의 하나.
※ 의사결정 지원 시스템(DSS, Decision Support System)
단순히 정보를 수집, 저장, 분배하기 위한 시스템을 넘어서 사용자들이 기업의 의사결정을 쉽게 내릴 수 있도록 사업 자료를 분석해주는 역할을 하는 컴퓨터 응용 프로그램이다.
Batch Processing
작업을 몰아두었다가 한번에 처리하는 시스템. 예:선거투표결과 추출, 게임 이벤트 아이템 일괄 지급 등
Batch 와 반대되는 개념으로 실시간으로 db의 데이터를 트랜잭션 단위로 갱신/조회하는 처리방식. 은행, 증권사 등에서 씀. 기존과 달리 다수의 client가 거의 동시에 이용할수 있도록 송수신자료를 트랜잭션단위로 압축한것이 특징.
DW: Data Warehouse
수년간 발생한 데이터를 모아서 주제별로 합쳐 분석할 수 있게 하는 통합시스템.
예) 운영데이터, 분산데이터, 시장데이터를 추출하여 DW를 구축하고 그걸 DSS나 OLAP로 분석
※Data Mart: DW의 하위단위라고 볼 수 있으며, DW는 중앙집중식 데이터 집합체의 개념을 가지나, data mart는 데이터 저장소의 역할을 하고 특정 목적을 위해 쉬운 접근성과 사용성을 가진다. DW는 기존 데이터를 어떻게 수집/분석하고 어떻게 재사용할 것인가에 초점을 맞춤
OLAP:OnLine Analytical Processing
위의 DW에서 데이터를 분석해서 의미있는 형태로 만들기 위한 과정및 도구. 의사결정 지원 시스템의 하나.
※ 의사결정 지원 시스템(DSS, Decision Support System)
단순히 정보를 수집, 저장, 분배하기 위한 시스템을 넘어서 사용자들이 기업의 의사결정을 쉽게 내릴 수 있도록 사업 자료를 분석해주는 역할을 하는 컴퓨터 응용 프로그램이다.
Batch Processing
작업을 몰아두었다가 한번에 처리하는 시스템. 예:선거투표결과 추출, 게임 이벤트 아이템 일괄 지급 등
2012년 3월 15일 목요일
OEL5.7에 oracle 9i R2를 깔면서 내린 결론
9i R2를 운용하려면 절대 rhel5 이상에 깔면 안된다!
os와 java의 상성이 안좋다. 어찌저찌 억지로 설치할순 있으나 그래도 문제점이 많이 남는다.패치시에 dbua마저 제대로 동작하지 않는다.
추후에 어떤 에러들이 나는지 기록할 예정. 허참 별의별 에러들이.
oracle 9i를 설치하려면 rhel3나 4를 추천한다.
os와 java의 상성이 안좋다. 어찌저찌 억지로 설치할순 있으나 그래도 문제점이 많이 남는다.패치시에 dbua마저 제대로 동작하지 않는다.
추후에 어떤 에러들이 나는지 기록할 예정. 허참 별의별 에러들이.
oracle 9i를 설치하려면 rhel3나 4를 추천한다.
2012년 3월 13일 화요일
띄엄띄엄 책 중요 포인트 요약중
2장.
*실무에서 가장 많이 사용되는 설치옵션- oracle database 10g, Enterprise edition 옵션중 파티셔닝,디벨롭킷.
*설치중 링크 에러시 로그 확인하고 조치를 취한 뒤 $ORACLE_HOME/bin/relink all 로 링크 재실행.
*데이터베이스 필수파일= 데이터, 컨트롤, 리두로그
*db 생성시에는 startup nomount.
*리두로그는 최소 2개의 그룹, 그룹당 1개의 멤버
*character set은 보통 KO16WIN949 or KO16KSC5601
*catalog.sql = 데이터 딕셔너리뷰 생성, catproc.sql = 필요패키지 생성?
*ASM=10g부터 생김
*RAW 장치=파일시스템을 만들기 전 단계인 RAW device 를 사용해 데이터파일로 사용. 많이 사용안됨, RAC 구성할땐 RAW로밖에 안됨. 여러 시스템에서 하나의 db에 접근해야 하는데 이건 RAW밖에 안됐음. 10g부터는 ASM도 가능하게 됨.
*오라클넷 사용시 가장 자주 쓰는게 로컬이름방식=Tnsnames.ora파일(클라이언트에 있음) 등록된 db정보 이용 접속(listener.ora 파일은 서버측)
3장.
요약불가, 팁정도만 기록함.
*Granule 단위-sga_max_size가 128M이하면 4M, 초과하면 16M. 예를 들어 sga_max_size가 130인 상태에서 데이터버퍼캐쉬를 32에서 40으로 늘리려고 해도 32+16인 48로 설정됨.
*공유풀 예약공간-실무에선 잘 안씀,보통은 기본값
*데이터버퍼캐쉬-성능을 위해 SGA에서 보통 제일 크게 잡아줌.
*데이터블록크기-db가 대용량화되어감에 따라 크게 설정하는 것이 일반적
*다중데이터버퍼캐쉬-테이블 수가 많으면 하나하나 적용하기 힘들어서 잘 안씀.
*리두로그 크기-1~10M 적당
*대형풀-필수는 아니지만 공유풀 부하 감소를 위해 사용하는것이 좋음
*ASMM(Automatic Shared Memory Management)-10g부터 생긴 기능. 공유풀,데이터버퍼,대형/자바풀 자동 조절.주의할 점은 최소값을 설정해서 메모리크기가 작게 설정되는걸 방지하는 것.
MMAN이 관리함(Memory MANager)
*실무에서 가장 많이 사용되는 설치옵션- oracle database 10g, Enterprise edition 옵션중 파티셔닝,디벨롭킷.
*설치중 링크 에러시 로그 확인하고 조치를 취한 뒤 $ORACLE_HOME/bin/relink all 로 링크 재실행.
*데이터베이스 필수파일= 데이터, 컨트롤, 리두로그
*db 생성시에는 startup nomount.
*리두로그는 최소 2개의 그룹, 그룹당 1개의 멤버
*character set은 보통 KO16WIN949 or KO16KSC5601
*catalog.sql = 데이터 딕셔너리뷰 생성, catproc.sql = 필요패키지 생성?
*ASM=10g부터 생김
*RAW 장치=파일시스템을 만들기 전 단계인 RAW device 를 사용해 데이터파일로 사용. 많이 사용안됨, RAC 구성할땐 RAW로밖에 안됨. 여러 시스템에서 하나의 db에 접근해야 하는데 이건 RAW밖에 안됐음. 10g부터는 ASM도 가능하게 됨.
*오라클넷 사용시 가장 자주 쓰는게 로컬이름방식=Tnsnames.ora파일(클라이언트에 있음) 등록된 db정보 이용 접속(listener.ora 파일은 서버측)
3장.
요약불가, 팁정도만 기록함.
*Granule 단위-sga_max_size가 128M이하면 4M, 초과하면 16M. 예를 들어 sga_max_size가 130인 상태에서 데이터버퍼캐쉬를 32에서 40으로 늘리려고 해도 32+16인 48로 설정됨.
*공유풀 예약공간-실무에선 잘 안씀,보통은 기본값
*데이터버퍼캐쉬-성능을 위해 SGA에서 보통 제일 크게 잡아줌.
*데이터블록크기-db가 대용량화되어감에 따라 크게 설정하는 것이 일반적
*다중데이터버퍼캐쉬-테이블 수가 많으면 하나하나 적용하기 힘들어서 잘 안씀.
*리두로그 크기-1~10M 적당
*대형풀-필수는 아니지만 공유풀 부하 감소를 위해 사용하는것이 좋음
*ASMM(Automatic Shared Memory Management)-10g부터 생긴 기능. 공유풀,데이터버퍼,대형/자바풀 자동 조절.주의할 점은 최소값을 설정해서 메모리크기가 작게 설정되는걸 방지하는 것.
MMAN이 관리함(Memory MANager)
피드 구독하기:
글 (Atom)